QStudio PRQL Quick Start Guide
 PRQL Quick Start by Rich Brown
PRQL Quick Start by Rich Brown
This tutorial demonstrates using QStudio a Free SQL Client to open an SQLite database and run PRQL queries against the tables. QStudio allows running PRQL against 30+ databases as it uses a translation layer to seamlessly convert queries. For more details see the QStudio PRQL support page.
The original source of this tutorial is Rich Brown via github and the source can be found here.
Background
Over the years, we have collected a ton of data - mostly from spreadsheets or PDF files, or retrieved from the Town, Vision or the Grafton County Register of Deeds. For example all the following files are in my Github repository.
- Lyme's Old-to-New values from the MS-1 reports
- Data "scraped" from Vision site
- Grafton County Register of Deeds
All these files have a similar format: a bunch of rows (usually representing parcels) with interesting data in the columns.
For example, I scanned all the Old-to-New documents for 2021 to 2024; they're in the "OldToNewValues" spreadsheet. If you look at that spreadsheet, you'll see these columns:
PID
Map/Block/Unit
Location (street address)
Owner
Code
OldValue
NewValue
Ratio
Difference
Year
Or look at the "Scraped Data" file. From time to time, I run a script that loads every page from Vision and plucks up the values for each property. It produces these columns:
PID
Owner
Street Address
Map/Block/Unit
Book/Page
Assessment
Appraisal
Lot size,
...
The Grafton County Register of Deeds file includes columns for:
ID
Date&Time
Date
Time
Type
Book&Page
Book
Page
Party1 (seller)
Party2 (Buyer)
...
The good side of spreadsheets
Spreadsheets are a very convenient way to view data. Everyone knows how to open and manipulate them. And lots of interesting data is reported in a spreadsheet.
You could consider putting each of the above into a separate tab of a spreadsheet. And if you got another source of data, you could add a new tab (with its columns and rows) to the spreadsheet.
The downsides of spreadsheets
But spreadsheets come with downsides, primarily because modifying a spreadsheet is (mostly) irreversible - it's very hard to get it back to its original state. For example:
To see the difference or ratio between old and new values, you could create a new column. But each time there's a new column, the "underlying data" gets changed.
Or sort by a column. But the act of sorting changes the underlying data of the spreadsheet. And putting the data back to its original state gets really hard.
Or, you don't particularly care about a particular column, say last year's assessed land value: that column just gets in the way. You could delete it - but maybe you'll want it later on.
What if there were a way that you can select only the columns you want, and create new columns with their own calculations, and sort every which way?
Using a database
That's where SQL databases come in. Each of those spreadsheets becomes a table in the database. The table's columns and rows exactly match the spreadsheet's columns and rows. When you use a database, you create queries that produce new results without changing the underlying data.
The fundamental rule of databases (their "super power") is that every operation starts with a table and creates a new (modified) table. Subsequent operations make further modifications to create yet another table. That new table doesn't get "added to the database". Instead, the database program just displays the final result, without changing the underlying tables.
And finally, a database query is simply a series of instructions that tell how to manipulate the tables. That query can be saved and re-executed at any time, or modified to answer different questions.
qStudio demonstration
qStudio is an application that lets you view and manipulate the tables of a SQL database. It's the first tool that I think is good enough to criticize - that is, all the prior ones were just too hard to use, with too many steps to get useful results. I like qStudio because it:
- Runs on Windows, Mac, Linux.
- Provides a good enough user interface. (Although qStudio's interface has some some sharp edges, they're easy to recognize and work around.)
- Uses PRQL (pronounced "Prequel") to make it MUCH simpler to write queries (SQL is the pits, you won't need to know it)
Playing with qStudio
Lesson #2 tells how to install qStudio, download and open the _Property_in_Lyme_ SQLite database, and then start making your own queries.
Install qStudio
On a Mac:
- Download the Mac version of qStudio from: https://randomneuronsfiring.com/wp-content/uploads/qStudio.zip
- Unzip the result to get the qStudio.app application
- Double-click the application. You will see a "unverified developer" (or similar) warning. Use System Preferences -> Privacy and Security to indicate that you trust the application. Click "Open anyway" if necessary. qStudio opens.
On a Windows machine:
- Download the Installer for Windows from the qStudio Downloads page: https://www.timestored.com/qstudio/download
- Run the installer in the usual way
- Using the command line, enter
winget install prqlcto install the PRQL compiler. - Open qStudio
Register for a free qStudio license When qStudio starts up, it requires you to register for a free account. Provide your email address and you will be taken to a page that displays a license code (a long string). Copy that string and paste it into the qStudio window.
Download the "Property in Lyme" SQLite database The latest copy of the database is always available from: https://raw.githubusercontent.com/TaxFairness/TaxFairness/refs/heads/main/Property_In_Lyme.sqlite
Open the "Property in Lyme" SQLite database in qStudio. To do this, drag the database's icon into the qStudio window (top left corner, but the bottom half of that pane).
(You might also download the Chinook database that is frequently used for examples. You can also drag the Chinook database to qStudio - it will work properly when both are opened.)
Playing with qStudio
qStudio is now running. Here are some hints for trying its features.
View the tables
Click any of the names of tables at the top-left of the window. The columns and rows appear at the bottom of the window. Interesting tables are:
- CleanScrapedData - a cleaned-up list of every parcel in Lyme, gleaned from information from the Vision database along with easement and frontage information.
- GraftonCtyRoD - all records from Grafton County Register of Deeds back to April 2019.
- LymeOldToNew - data from the (original) 2024 MS-1. I will update when we are permitted to view the info.
Create and edit queries
The basic process is:
- Create a new file in qStudio (File -> New File)
- Save as
qStudioTest.prql(".prql" suffix is important) using File -> Save As... I recommend you save it to a new folder on the Desktop so it's easy to find later. - Enter a query. Start simple with
from LymeOldToNew- this statement just displays all the rows and columns from theLymeOldToNewtable. - Save the file with Cmd-S on Mac; Ctl-S on Windows
- Execute the query (Cmd-E / Ctl-E)
- You may be prompted with a request to install the "SQLite driver". Allow it to happen.
- The result from the query appears in the bottom "Result" pane. If the Result pane is not visible, choose Windows -> Result
- Edit the query by typing in the window. Save and Execute it as above.
Enhancing your query
Here are examples taken from the first lesson. You can experiment with qStudio by modifying the queries as shown below:
Note - these examples use the PRQL language (pronounced "Prequel"), not SQL. The PRQL Reference Book gives full details on creating queries.
Select two columns from the LymeOldToNew table, ignoring the rest
Do this by adding a select statement at the bottom.
Note that the select statement requires a list
enclosed within { ... } that has column names
("LO_Location" and "LO_Owner") separated by ",".
from LymeOldToNew
select {
LO_Location,
LO_Owner,
}
Here's the way to think about the query above.
The statement from LymeOldToNew starts a "pipeline"
with the contents of that table.
It passes it to the next statement (select ...)
that modifies the table,
by retaining only the two named columns (with all the rows)
that could be passed along to any subsequent statement.
Note that PRQL doesn't care about line breaks.
A statement can be on one or many lines:
the following is equivalent to the above:
select { LO_Location, LO_Owner }
Select a couple more columns
Add more column names between the { ... }, separated by commas.
Trailing commas are allowed, even if no other column name
appears afterwards.
from LymeOldToNew
select {
LO_Location,
LO_Owner,
LO_OldValue,
LO_NewValue,
LO_Year,
}
The qStudio result now shows five columns, the first two plus the three new ones. The Result pane shows them in the order they are listed in the query.
Create a new column named "difference" of the new to old values
To do this, add a new line with the column name ("difference")
followed by =, and then the calculation.
from LymeOldToNew
select {
LO_Location,
LO_Owner,
LO_OldValue,
LO_NewValue,
LO_Year,
difference = LO_NewValue - LO_OldValue,
}
_Note that the new "difference" column in the result is just as "real" as any of the original "LO_xxx" columns._
Note too, that the comma at the end of the line is optional, but recommended because you can comment out any line (see below) without hassle.
OK. That's all very interesting, but which property had the biggest change? Let's sort by the "difference" field. Add this line to the end, then re-execute the query:
sort {difference}
This sorts the rows by the value in the "difference" column.
To reverse the sort, use sort { -difference }.
Oh, but that shows many different years. Let's just look at 2024. Add this line to the end:
filter (LO_Year == 2024)
_This includes any rows where the LO_Year is equal (==) to 2024.
(The double-equal is required.)
To exclude the year 2024, you can use "not-equal" !=.
And the >, >=, <, and <= operators work as expected._
Commenting out lines
Sometimes you want to temporarily (or permanently)
remove a line or group of lines from a query.
PRQL uses # as the comment character.
When it appears, the remainder of that line will be ignored.
There is a keyboard shortcut -
Cmd-/ (Mac) or Ctl-/ (Windows) -
that comments out/uncomments the lines that are selected.
Export to Excel
One cool feature of qStudio is that you can export the results directly to Excel. The Result pane opens directly in a new workbook. To do this, click the small Excel icon in the top-right of the window. It's the second icon on the right side of the image below.

Further observations
PRQL statements "transform" the table they receive by modifing it in some way and passing it along to the next statement. This is the power feature of PRQL: the statements can be "stacked" to form a pipeline that continally modifies the data as it passes through to produce a final result.
The
filterstatement could have been placed much earlier in the query. In fact, it could have immediately followed the initialfrom ...That would have removed all the other years prior to passing them to the firstselect- and in the end, the result would have been identical.Similarly, the
sort ...statement could have been placed anywhere in this pipeline. From that point in the pipeline, all the rows would have remained in the same order.Finally, a bit of "PRQL lingo":
- Since PRQL statements "transform" a table, they're also called transforms.
- Tables are also called relations.
- A tuple is the PRQL term for column names that are
enclosed in
{ ... }. For example, it's proper to say theselecttransform requires a "tuple" (instead of requiring a "list").
Common Problems
You may encounter little problems with qStudio and PRQL. Here's how to work around them.
PRQL queries
PRQL is a terrific language for writing queries. When the query is correct, it works great.
But its diagnostic messages are often arcane. When things aren't correct, it displays the error in a "red bar", and displays details below. Here are some common error indications you'll encounter and what to do about them:
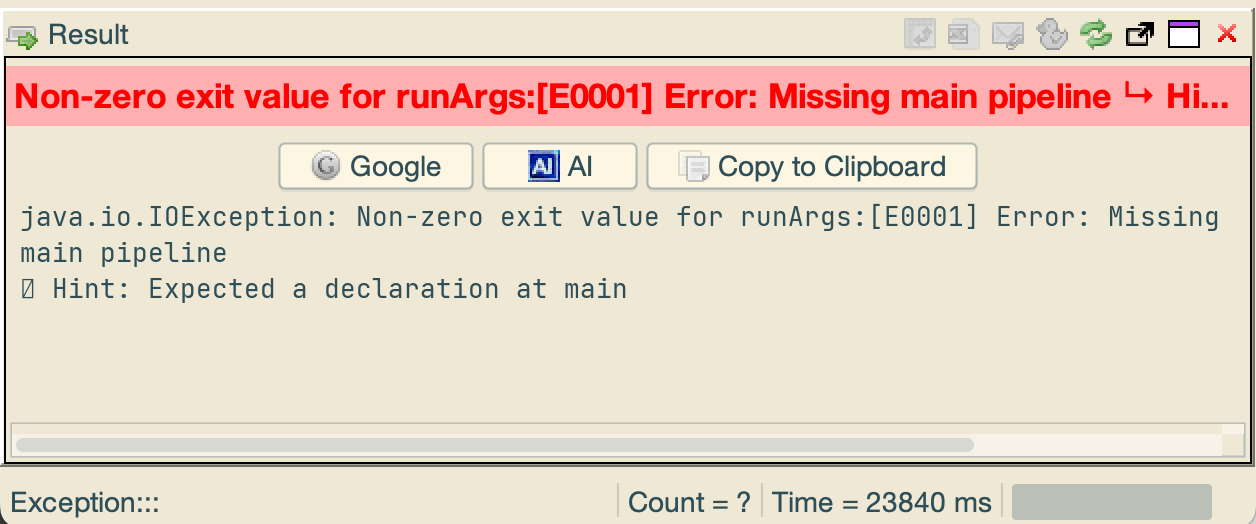
Missing main pipeline
The screen shot below shows [E00001] Error: Missing main pipeline
in the bottom half of the window.
This is most likely caused by trying to execute an empty query or a commented-out line. Click somewhere in the query window (to un-select) and re-execute.
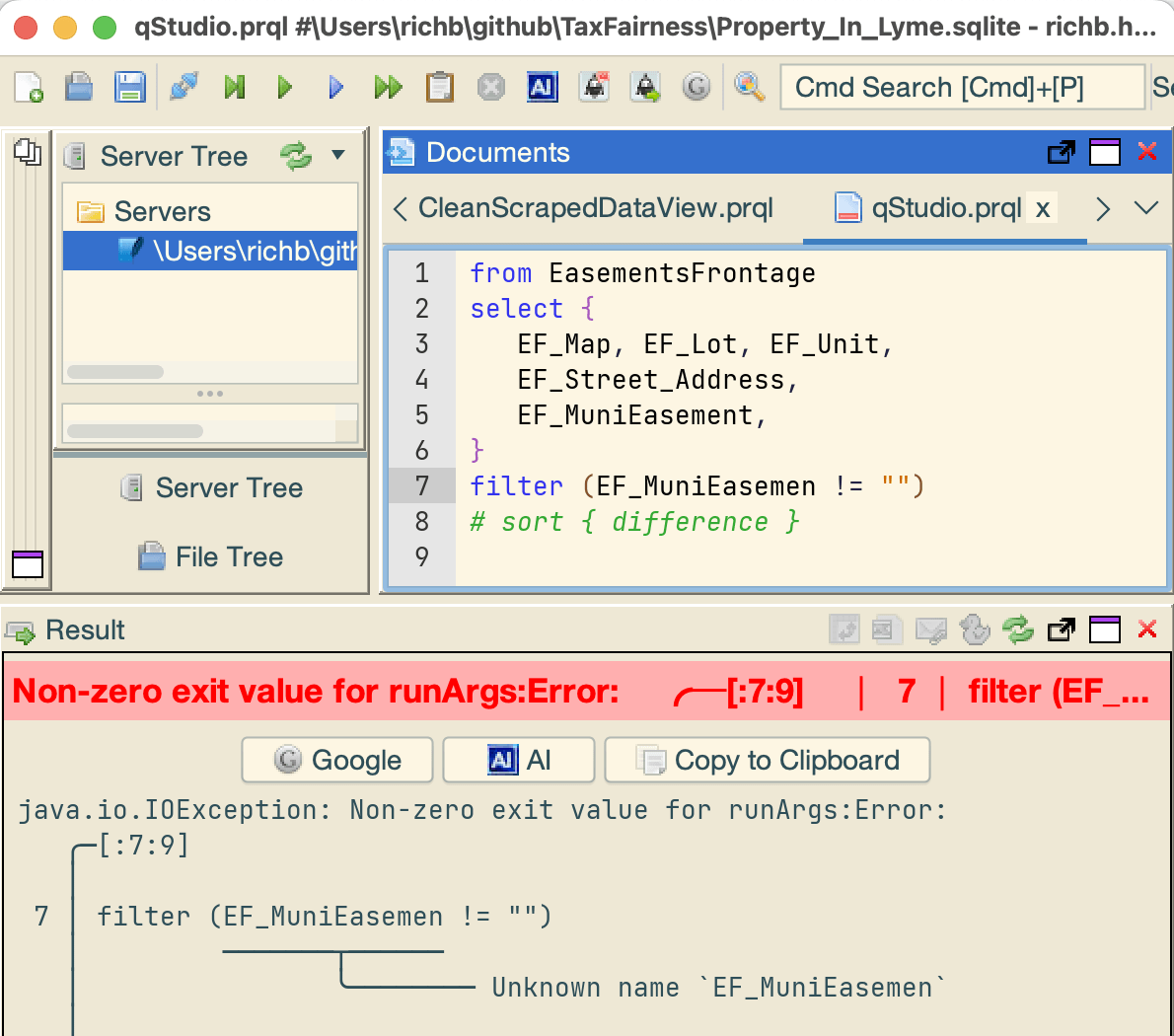
Unknown name
PRQL is case-sensitive and cares about spelling.
The error message (in the image below)
Unknown name 'EF_MuniEasemen' shows that the
column name wasn't recognized because it was misspelled.
Similarly, if it had been typed in lower-case as ef_munieasement
it also would have given the "Unknown name" error.
To correct the error, simply fix the typo and re-execute.
Unknown name (reason #2)
Correcting line 7 above (adding back the "t") but
changing the query in line 5 (within the select)
to EF_MuniEasemen also gives an "Unknown name" error.
(Try it.)
But qStudio still reports it on line 7.
The reason is a bit subtle:
the select transform passes along the named columns,
including one named EF_MuniEasemen (without the "t").
Yet the filter transform is looking for a column name
that has a "t", and so it gives the "Unknown name" error.
To correct the error, simply fix the typo and re-execute.
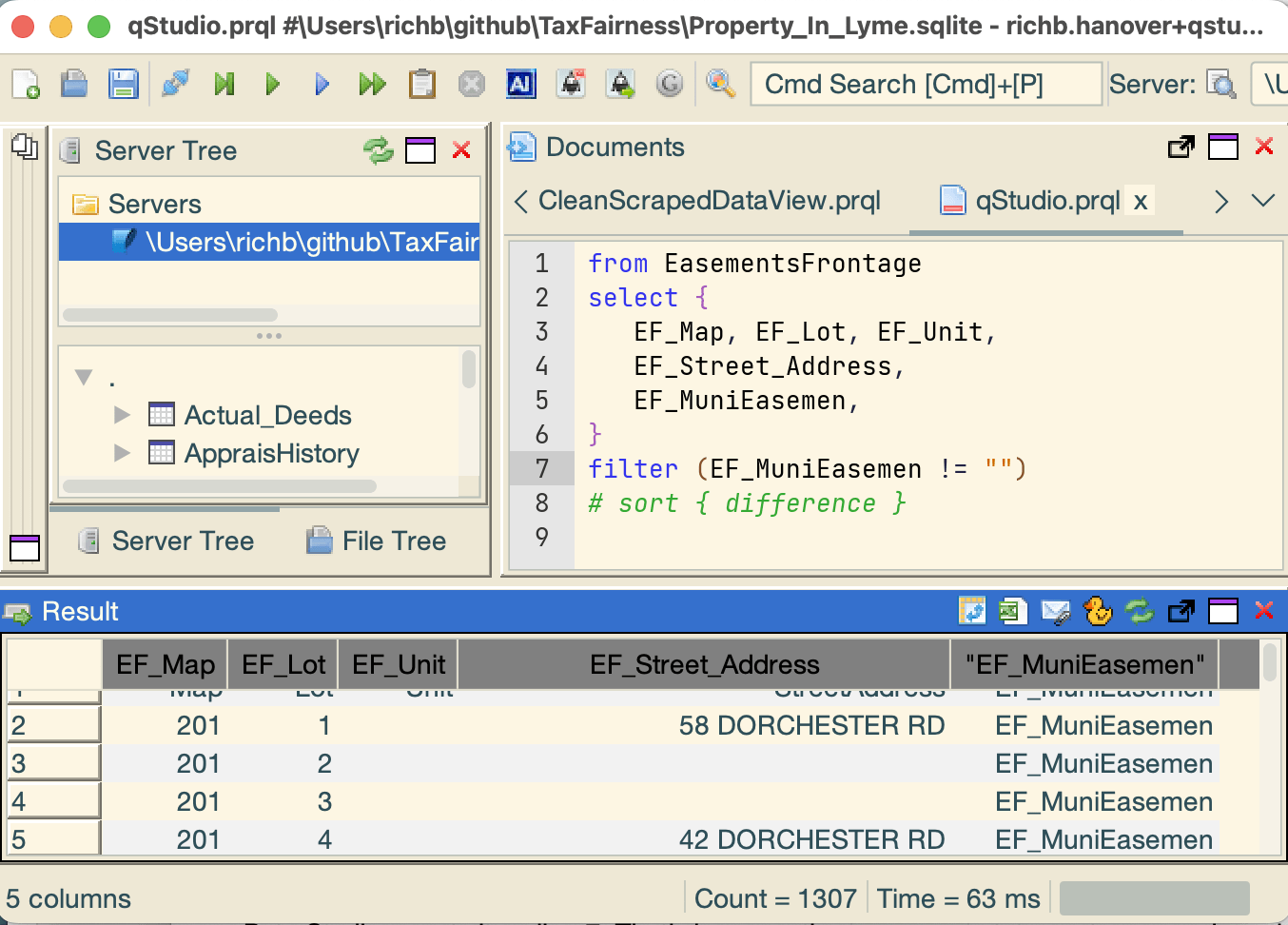
Column heading in "..."
Note: neither qStudio nor PRQL have any idea of the actual
column names in the database.
You must type them correctly in the query.
If a column name is consistently misspelled
(for example, if both lines have EF_MuniEasemen),
qStudio will dutifully create and execute the query.
When the response returns, the database simply substitutes the misspelling for the column name and the contents of the column. In the screen shot below, notice:
- the column heading has its name in quotes (
"EF_MuniEasemen"), an indication that there's no such column name in the table - the column contains the string
EF_MuniEasemenfor all its rows.
To correct the error, simply fix the typo(s) and re-execute.
Result window workarounds
The Result window displays table contents and the results of a query. Sometimes qStudio doesn't act quite as expected.
Some columns are too wide in Result window
Drag the separator between columns to adjust their width.
Result window doesn't always show a table
If you click a table name at the top left, the Result pane (bottom of the window) shows the first 1,000 rows of that table. When you execute a query, the Result pane shows the results (as it should).
But if you then click a table name again, the Result pane does not change. To work around it, click a different table name, then the one you want. The Result pane changes to the desired table.
Result window only shows top 1,000 rows of a table
When you click a table name,
the Result window shows the first 1000 rows.
There doesn't seem to be a way to see more rows,
or the next 1000 rows.
To work around this, execute the query from <table-name>
then all rows appear.
Result window doesn't pop out
Sometimes, clicking the "pop-out" icon of the Result window (black rectangle with arrow - see the screen shots above) causes it to become a separate window. Sometimes it doesn't. I don't know why.
More Transforms
PRQL has more transforms (statements) that modify a table as it passes through its pipeline. Much of the discussion below comes from the PRQL Reference Tutorial
We have already introduced several PRQL transforms. Let's review what each does and how each changes the "shape" of the table:
from- begins a pipeline and passes the entire table to the next transform.select- Changes the number of columns by retaining only those named within the tuple (the list of column names inside the{ ... }) but never the number of rows.filter- Changes the number of rows by excluding the ones that don't match the criteria. Never changes the number of columns.derive- Changes the number of columns by adding a new column, calculated from other columns in the row. Never changes the number of rows.sort- Changes the order of the rows, but leaves the number of rows and columns unchanged.
This lesson talks about these new transforms.
take
The take transform picks rows to pass through
based on their position within the table.
The number of columns is unchanged.
The set of rows picked can be specified in two ways:
- a plain number
x, which will pick the firstxrows, or - an inclusive range of rows
start..end
For example:
from invoices
take 4 # takes the first four rows
# - or -
from invoices
take 4..7 # takes rows 4, 5, 6, and 7
aggregate
The aggregate transform takes a tuple (a list of column names)
and “distills down” data from all the rows into a single row.
This is frequently used for statistical analysis.
from invoices
aggregate { sum_of_orders = sum total }
In the query above, the "invoices" table has a column named total
(perhaps it's the total of a single order).
It sums all the values in the total column to produce
a single row.
The number of columns is equal to the number of items within the tuple.
In the example above, the result would be one column.
In the example below, the resulting table has two columns -
sum_of_orders and avg_of_orders
from invoices
aggregate {
sum_of_orders = sum total,
avg_of_orders = average total,
}
group
The group transform performs a set of operations on "groups" of rows
based on some characteristic.
You might use group to analyze data by city or some other value.
The group transform retains all the columns:
the number of rows is equal to the number of different combinations
within the group characteristic (say, the number of different cities).
See the "grouping" section of the PRQL docs for more information.
join
The join transform combines the columns of two tables together
"side-by-side" based on related columns of each table.
It is often useful to "join" two separate tables that each have
columns with interesting data using common parameters,
and then use select to extract the interesting columns.
The join transform adds columns to the result
(it contains all the columns from both tables).
The number of rows varies based on the data within the tables
and the operators used to join the tables.
See the "join" section of the PRQL docs for more informatioin.
Practical Example
Let's try a practical example of using PRQL with qStudio.
The LymeOldToNew table of the _Property_in_Lyme.sqlite_ database
has all the parcels in Lyme, showing
their old and new assessments for each of the years 2022, 2023, and 2024.
(In fact, there were two sets of 2024 data, one from August,
and another in October that corrected many values.)
Question How can we understand what properties changed value between the August and October 2024 readings?
The following steps show the iterative process for reviewing and massaging data sets to produce the desired information. As you work through the steps, you may find oddities in the underlying data that need to be tidied up. The beauty of the PRQL lanuage (as opposed to using SQL) is that you can focus on the broad picture and let PRQL take care of the details.
Examine the LymeOldToNew table
Let's first review the data that we have available. (Be sure to retrieve a fresh copy of the _Property_In_Lyme.sqlite_ database from the repository and add it to qStudio.)
- Click the
LymeOldToNewtable in the upper-left corner of qStudio - Notice that it has columns for address, owner, old and new values, and a year and CollectedOn column. (There are other columns that can mostly be ignored.)
- We can use those last two columns to make comparisons between data from different years by creating a table that contains only rows where the year is 2022, or where the CollectedOn column has a certain date.
Create a table for the August 2024 rows
PRQL has the ability to create a new table from an existing one.
The let statement does this.
It assigns a name to a set of transforms that result in a table.
To start, create a new PRQL query. Always begin like this:
- Create a new query file. Within qStudio, choose File -> New,
save it as
AugToOct.prqlon the Desktop. (The.prqlsuffix is required so that qStudio treats the lines as a PRQL query.) - Add the following lines
- Execute the query (with Cmd-E or Ctl-E)
let aug24 = (
from LymeOldToNew
)
from aug24
At this point, the aug24 table has all the rows of its parent table.
Let's keep only the rows that were collected on August 29, 2024.
To do this, add the new line below.
The @2024-08-29 is special notation for representing a date.
let aug24= (
from LymeOldToNew
filter (LO_CollectedOn == @2024-08-29)
)
from aug24
Now the aug24 table contains only rows where the LO_CollectedOn column
has that date.
We don't want most of the columns - let's select the ones we want:
let aug24= (
from LymeOldToNew
filter (LO_CollectedOn == @2024-08-29)
select {
PID = LO_PID,
Location = LO_Location,
AugOld = LO_OldValue,
AugNew = LO_NewValue,
}
)
from aug24
Now the aug24 table contains only four columns, and only the
rows from August 29, 2024.
Keeping the PID column is especially important -
we'll see why in a moment.
You'll also see that the column names in the result
no longer have the "LO_" prefix
because we assigned new names to them:
PID, Location, AugOld, and AugNew.
Create an October table
Using a similar process, we can create a table that holds the October 2024 rows. Here's the completed example.
let oct24 = (
from LymeOldToNew
filter (LO_CollectedOn == @2024-10-31)
select {
LO_PID,
OctOld = LO_OldValue,
OctNew = LO_NewValue,
}
)
from oct24
The oct24 table has just three columns:
its PID (we left its name as "LO_PID")
as well as the old and new values.
(You will probably have to comment-out (with Cmd-/ or Ctl-/)
the earlier from aug24 line.)
Use join to combine those tables
The join transform combines two tables, side-by-side,
using one or more criteria to "match" the rows.
In this case, we'll use the PID values -
they're the Parcel ID in the property tax database that
uniquely identifies each parcel.
Here's what we'll add to the query:
from aug24
join oct24 (PID == LO_PID)
The way to think about the above is, "Start with the aug24 table,
and join ("combine") it with the rows of the oct24 table,
using the values of each table's PID columns to determine
which of the rows to connect."
The process the computer follows is tedious, but straightforward:
Start with the first row of aug24 - find its PID (it happens to be 1).
Find a corresponding row (with a LO_PID of 1) in oct24
and place both rows side-by-side in the result.
Then examine each subsequent row of aug24 and combine with a
corresponding row of oct24 where their PID values match.
The resulting table has seven columns: the four from aug24
and three from oct24
Try this now: Type the two lines above into qStudio,
below the two table definitions and execute the query.
(Comment out any earlier from... lines.)
We're now starting to get useful data.
Notice the following: the values in the PID columns match;
the AugOld and OctOld values always match;
and that sometimes the AugNew and OctNew values don't.
Clean up the data a little bit
As you scroll through the results, you'll notice a lot of
lines that are blank, or have only OctOld and OctNew values.
These result from somewhat poor data preparation.
(Those lines happen to be the totals of the old and new columns that
were mistakenly included in the raw data files.)
It might be possible to go back to the source data, clean it up, and update the database. But sometimes, that's not possible: the data comes from from a source that cannot be changed.
But there's another way: we can just adjust the query to leave out those lines. In this case, all the PID values are empty. Add this statement to the bottom of the query:
filter (aug24.PID != '')
This transform means, "filter (and pass through) all the PID values that are not blank (''). Notice that all those nearly-blank lines are gone.
Note: The aug24.PID notation is a way to specify the column named
PID that came from the aug24 table.
(Tables of a join may well have identical column names -
using the notation tablename.columnname helps indicate which
column to use from the desired table.)
Find "new" values that don't match
It's hard to scan a table of numbers,
comparing values in different columns.
The computer can do it for us.
We can make a new column using the derive transform
that represents the difference between two columns.
Add this line to the end of the query:
derive AugToOctDiff = OctNew - AugNew
This creates a new column AugToOctDiff that contains the
difference between the two columns named there.
That does half the job: the results show lots of rows where the difference is zero - that is, where the August and October values are the same. Let's retain only the rows where the difference is non-zero.
filter (AugToOctDiff != 0)
This result retains only the rows where the difference is non-zero. But again, it's hard to make sense of the information, since the rows seem to be in a random order. Let's sort by the difference column:
sort { AugToOctDiff }
The result now shows the property value changes, sorted by the difference between August and October.
A little more "data cleaning"
The result also has a LO_PID column left over from
the oct24 table.
It was critical to performing the join operation,
but is no longer needed.
It's also confusing to others reading the results
("What's this LO_PID thing? Do I need to know about it?")
Better to take it out.
There's a way to use the select transform to exclude
the named columns instead of retaining them.
Place a ! in front of the tuple/list to designate the columns
to exclude.
select !{ LO_PID }
This removes the LO_PID column, while retaining all the other columns.
Summary
This exercise shows how qStudio and PRQL allow you to investigate
a data set interactively.
You can view the full data set, then filter the rows,
select the columns, and
join rows together to get a result.
The original source of this tutorial is Rich Brown via github and the source can be found here.