April 18th, 2026 by admin
QStudio 5.07 has been released:
March 7th, 2026 by admin
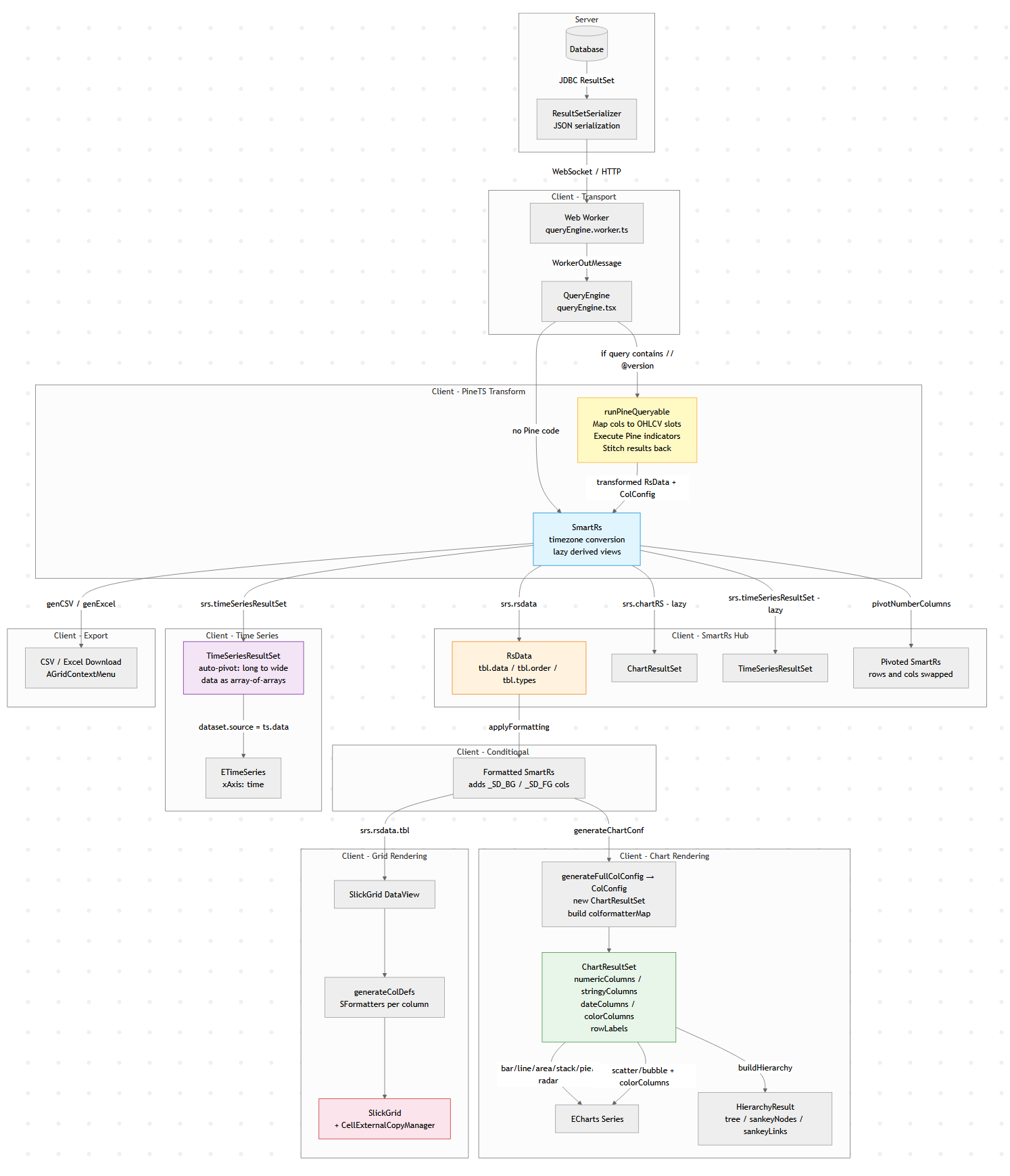
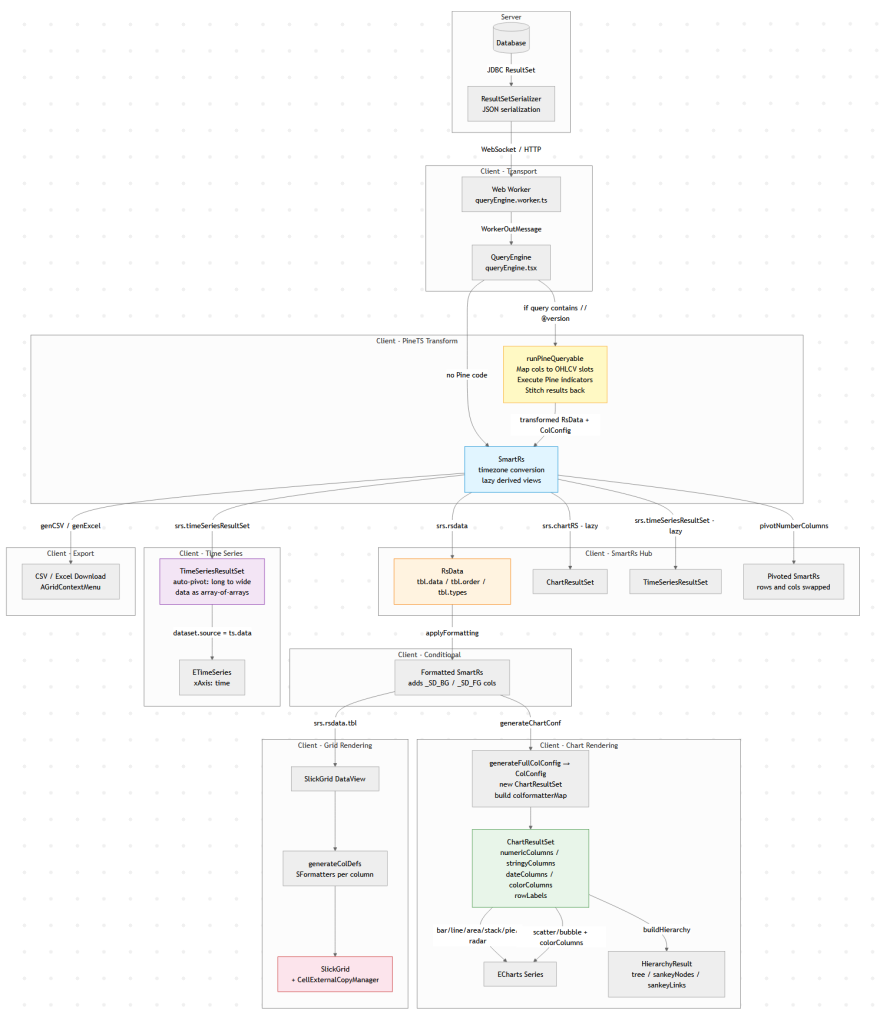
Modern data tools look simple: run a query, show a table, maybe draw a chart.
But under the hood there is usually a surprisingly complex data pipeline transforming raw query results into tables,
charts, exports, and derived views.
This diagram below is Pulse’s client-side data pipeline (adding the server side would double it).
Why does a “simple” data tool need all this? Because the same query result gets consumed in fundamentally different ways:
1. The table must show data as it came from the database.
2. Users apply formatting – decimal places, thousands separators, or advanced renderers like sparklines and heatmaps.
3. When they export to Excel, they want full numeric precision back (not the rounded display value), and sparklines replaced with raw arrays like `[2,4,5]`.
4. A time-series chart might append new rows to the end of a live stream. To handle that efficiently, we heavily optimize for the append-only case rather than re-rendering from scratch.
6. A Time-Series transform can compute indicators like MACD or Bollinger Bands on the raw result before it ever reaches the chart.
Each of these is a different transformation of the same source data, and they all need to stay in sync when the query refreshes.
A Concrete Example: One Query, Four Representations
Say you query a trades table:
SELECT timestamp, symbol, price, volume FROM trades WHERE timestamp > now() - 01:00:00
That single result set flows through the pipeline to produce:
– A live-updating table with prices formatted as `$1,234.56` and volumes with thousand separators, updating in-place as new trades arrive via WebSocket.
– A time-series line chart of price by symbol, where the engine auto-pivots the long-form result (one row per trade) into wide-form (one column per symbol) – no `PIVOT` clause needed in your SQL.
– A Pine Script overlay computing a 20-period moving average on price, injected as a new series before the chart renders.
– An Excel export where the user gets raw timestamps (not the `HH:mm:ss` display format), full decimal precision, and no HTML artifacts.
All four stay synchronized. When the next WebSocket push arrives with new rows, each branch of the pipeline updates – the table appends, the chart extends, the treemap re-aggregates – without re-running the query.
Why Data Engineers Should Care
If you’ve built internal tools, you’ve probably hit the same tensions: display formatting vs. export fidelity, append-optimized rendering vs. full re-render, flat SQL results vs. hierarchical visualizations. These are data transformation problems, and the solutions look a lot like what you’d build in a backend ETL pipeline, just running at 60fps in the browser.
The lesson: even “simple” analytics UIs hide a real data pipeline. And the more data-literate your users are, the more branches that pipeline grows.
January 26th, 2026 by admin
Pulse 3.36 Adds support for icons and images within tables:
Demonstrated in the video and multi-column sorting and real-time filtering.
January 17th, 2026 by admin
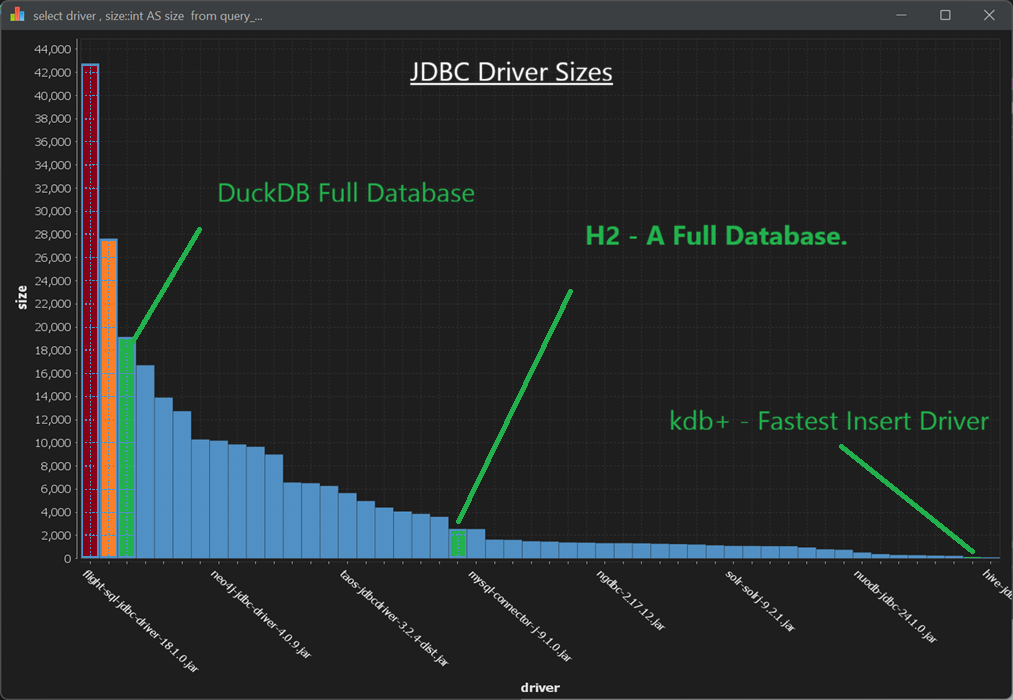
Size Isn’t Everything with Databases – Nor When It Comes to Database Driver size.
With QStudio and Pulse, we get to work hands-on with 30+ databases. That gives us a lot of appreciation for teams that do more with less – especially some of the smaller teams building compact databases and drivers that deliver an outsized amount of value.
In both Pulse and QStudio, we bundle a core set of JDBC drivers and optionally download others when a user adds a specific database. We do this deliberately to keep the applications lightweight. We care about every megabyte and don’t want to bloat either our product or our users’ SSDs.
Database Driver Size
Notice:
- DuckDB – An entire database that is smaller than both the Snowflake and the Arrow/flight SQL driver.
- H2 – Another full database (Java-specific) that is smaller than roughly a third of the drivers we ship.
- Kdb+ – Supports JDBC and has the fastest industry wide bulk inserts while being one .java file (1900 lines, 60KB)
Obviously, a smaller driver or database isn’t always “better” in isolation. But having worked closely with these three in production settings, we can say they are exceptional pieces of engineering. The performance these teams achieve with such compact codebases is a testament to strong engineering discipline and a relentless focus on efficiency end-to-end. Huge congratulations to the teams behind them.
Scale matters but Efficiency is what makes scale sustainable.
Database Driver Size
Full Sizes (in KB):
42776 flight-sql-jdbc-driver-18.1.0.jar
27644 snowflake-jdbc-3.13.6.jar
19144 athena-jdbc-3.2.0-with-dependencies.jar
16696 kyuubi-hive-jdbc-shaded-1.7.1.jar
13904 ignite-core-2.15.0.jar
12728 sqlite-jdbc-3.42.0.0.jar
10284 kylin-jdbc-5.0.0-alpha.jar
10180 neo4j-jdbc-driver-4.0.9.jar
9856 trino-jdbc-422.jar
9652 presto-jdbc-0.282.jar
8984 redshift-jdbc42-2.1.0.28.jar
6564 jt400-20.0.0.jar
6504 presto-jdbc-350.jar
6268 mongodb-jdbc-2.0.2-all.jar
5652 taos-jdbcdriver-3.2.4-dist.jar
4964 gemfirexd-client-2.0-BETA.jar
4400 ojdbc8-19.19.0.0.jar
4060 jdbc-1.30.22.3-jar-with-dependencies.jar
3856 omnisci-jdbc-5.10.0.jar
3600 derby-10.15.2.0.jar
2556 h2-2.2.224.jar
2540 mysql-connector-j-9.1.0.jar
1628 hsqldb-2.7.2-jdk8.jar
1608 hsqldb-2.7.2.jar
1488 jdbc-3.00.0.1-jar-with-dependencies.jar
1456 redis-jdbc-driver-1.4.jar
1380 clickhouse-jdbc-0.6.0.jar
1368 jdbc-1.30.22.5-jar-with-dependencies.jar
1324 ngdbc-2.17.12.jar
1324 ngdbc-2.17.10.jar
1308 mssql-jdbc-10.2.1.jre8.jar
1268 avatica-core-1.17.0.jar
1240 clickhouse-jdbc-0.4.6.jar
1204 terajdbc-20.00.00.11.jar
1136 sqream-jdbc-4.5.9.jar
1084 solr-solrj-9.2.1.jar
1080 solr-solrj-9.3.0.jar
1064 postgresql-42.7.4.jar
1060 jdbc-4.50.4.1.jar
952 snappydata-store-client-1.6.7.jar
792 x-pack-sql-jdbc-7.9.1.jar
752 crate-jdbc-2.7.0.jar
516 nuodb-jdbc-24.1.0.jar
380 ucanaccess-5.0.1.jar
300 clickhouse-jdbc-0.2.6.jar
284 taos-jdbcdriver-3.2.1.jar
248 csvjdbc-1.0.40.jar
228 ignite-core-3.0.0-beta1.jar
124 lz4-pure-java-1.8.0.jar
100 hive-jdbc-1.2.1.spark2.jar
December 6th, 2025 by admin
QStudio 5.0 is now Open Source after 13 years of development!
QStudio remains a fast, modern SQL editor supporting over 30 databases including MySQL, PostgreSQL, DuckDB, QuestDB, and kdb+/q. Version 5.0 continues our focus on performance, analytics and extensibility now with an open community behind it.
🎉 QStudio Is Now Open Source
After 13 years of development, QStudio is now fully open source under a permissive license. Developers, data analysts and companies can now contribute features, inspect the code, and build extensions.
Open Source Without the Fine Print.
No enterprise edition. No restrictions. No locked features. QStudio is fully open for personal, professional, and commercial use.
New Features with 5.0
New Table Formatters, Better Visuals, Better Reporting
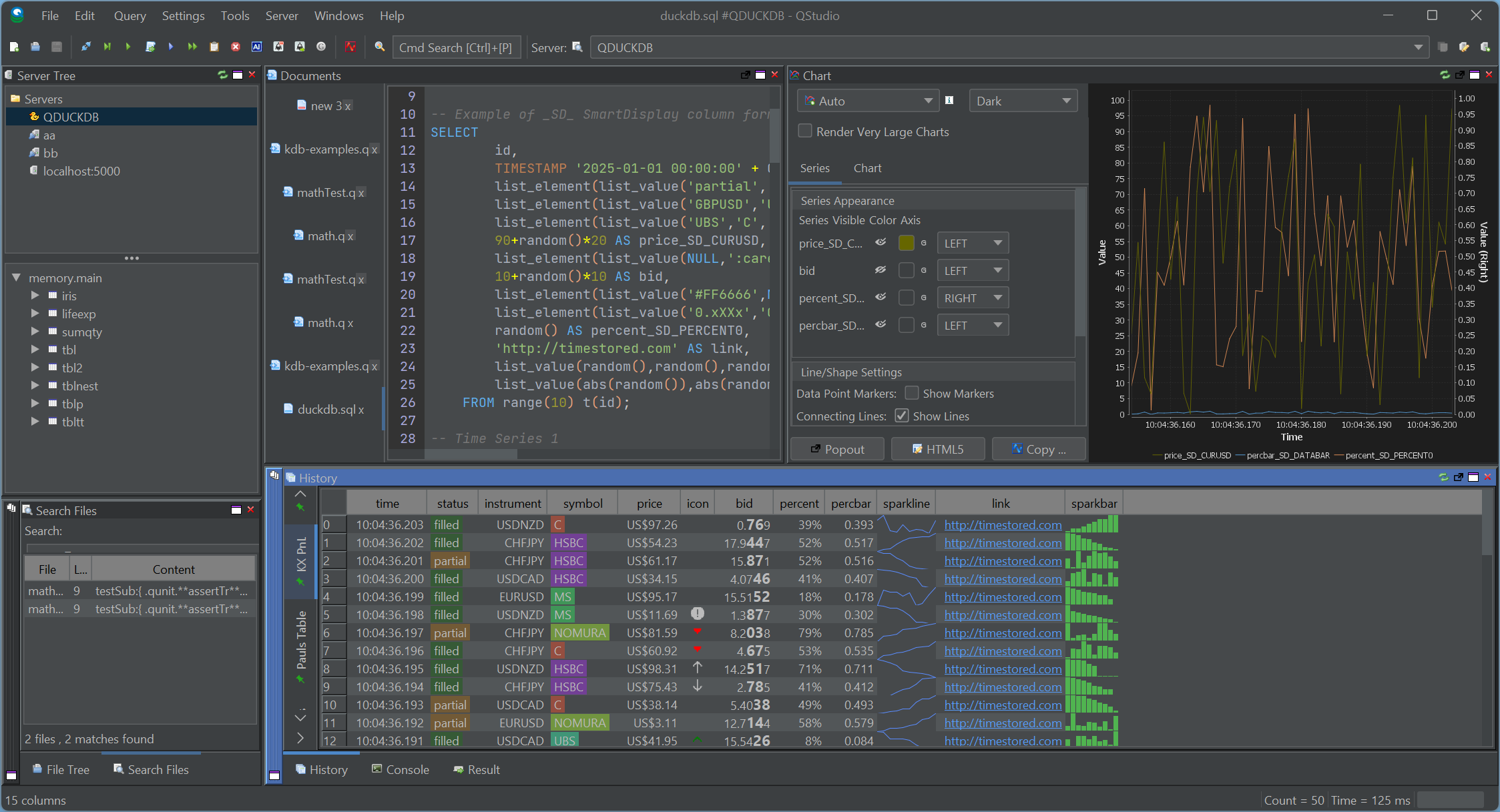
 SmartDisplay is QStudio’s column-based automatic formatting system. By adding simple _SD_* suffixes to column names, you can enable automatic number, percentage, and currency formatting,Sparklines, microcharts and much more. This mirrors the behaviour of the Pulse Web App, but implemented natively for QStudio’s result panel.
SmartDisplay is QStudio’s column-based automatic formatting system. By adding simple _SD_* suffixes to column names, you can enable automatic number, percentage, and currency formatting,Sparklines, microcharts and much more. This mirrors the behaviour of the Pulse Web App, but implemented natively for QStudio’s result panel.
Spark Lines + Micro Charts

Comprehensive Chart Configuration
Fine-tune axes, legends, palettes, gridlines and interactivity directly inside the chart builder.
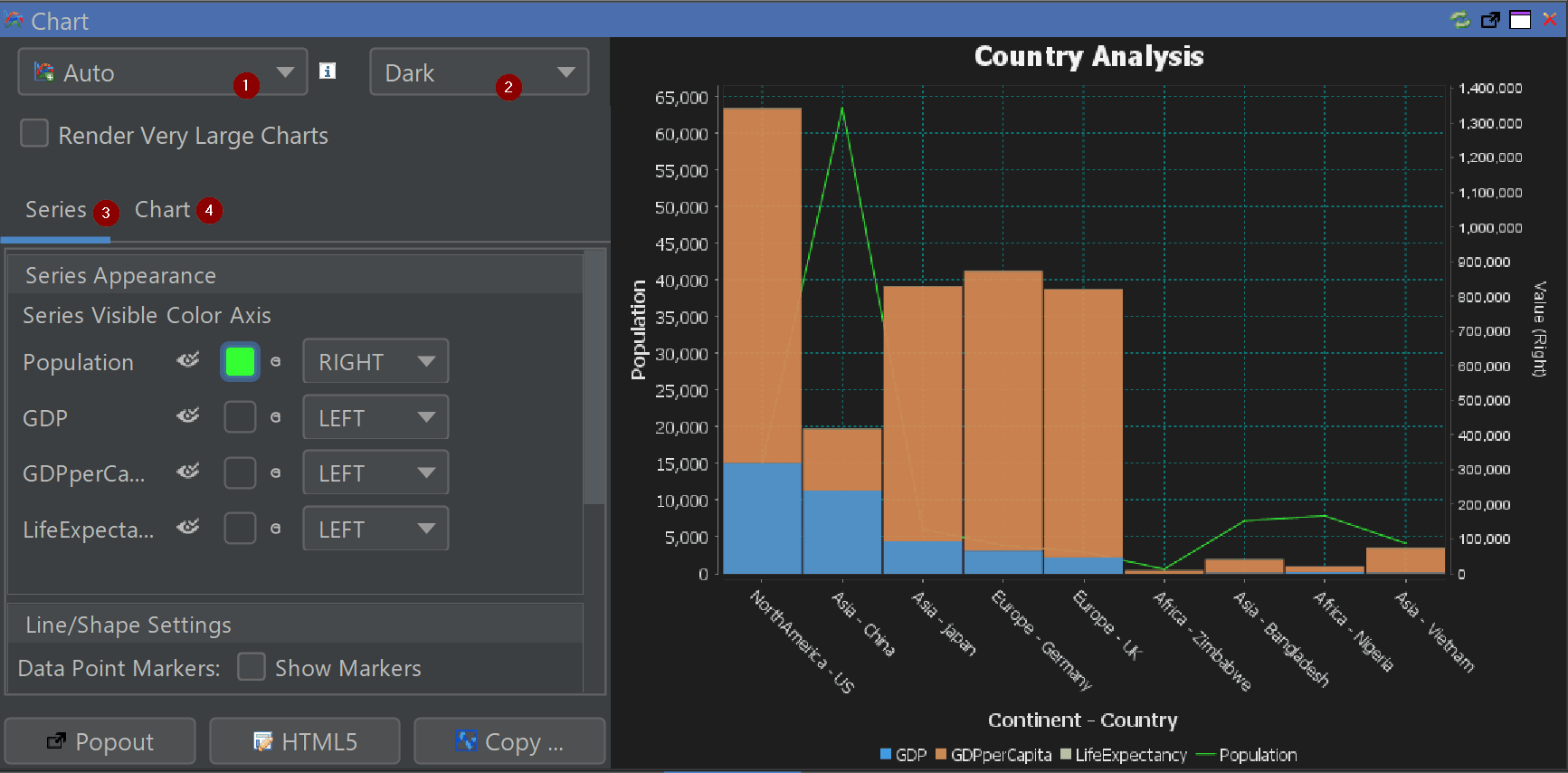
New Chart Themes
Excel, Tableau and PowerBI-inspired styles for faster insight and cleaner dashboards.

Other Major Additions
- Back / Forward Navigation — full browser-like movement between queries.
- Smart Display (SD) — auto-formats tables with min/max shading and type-aware formatting.
- Conditional Formatting — highlight rows or columns based on value rules.
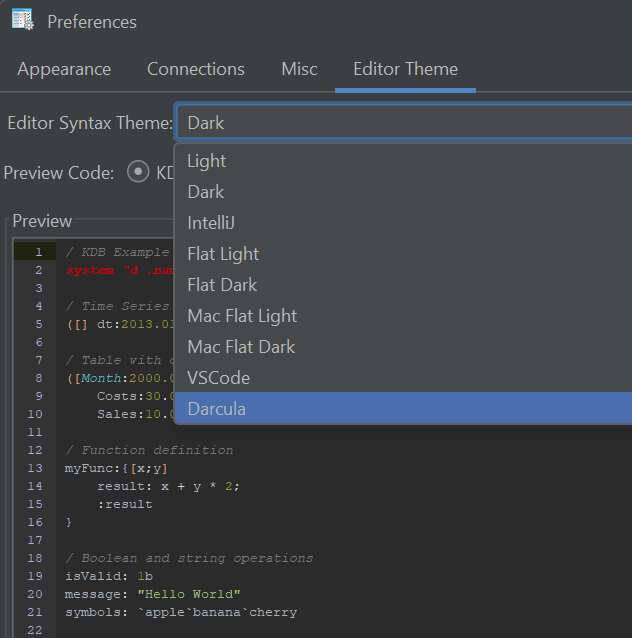
- New Code Editor Themes — dark, light and popular IDE-style themes.
- Extended Syntax Highlighting — Python, Scala, XPath, Clojure, RFL, JFlex and more.
- Improved kdb+/q Support — nested / curried functions now visible and navigable.
- Search All Open Files (Ctrl+Shift+F)
- Navigation Tabs in Query History — with pinning.
- Improved Chinese Translation
- DuckDB Updated to latest engine.
- Hundreds of minor UI and performance improvements
- Legacy Java Removed — cleaner, modern codebase.
Code Editor Improvements
Better auto-complete, themes and tooling for large SQL files.
Pinned Results
Pin results within the history pane for later review or comparison.
Search Everywhere
Control+Shift+F to search all open files and your currently selected folder.
Our History
- 2013–2024: QStudio provided syntax highlighting, autocomplete, fast CSV/Excel export and cross-database querying.
- Version 2.0: QStudio expands support to 30+ Databases.
- Version 3.0: Introduced DuckDB integration, Pulse-Pivot, Improved export options.
- Version 4.0: Introduced SQL Notebooks and modern visuals.
- Version 5.0: Open Source + hundreds of improvements across charts, editing, navigation and data analysis.
We aim to create the best open SQL editor for analysts and engineers. If you spot a bug or want a feature added, please open an issue
November 27th, 2025 by admin
Pulse 3.28 is now released. (Release notes)
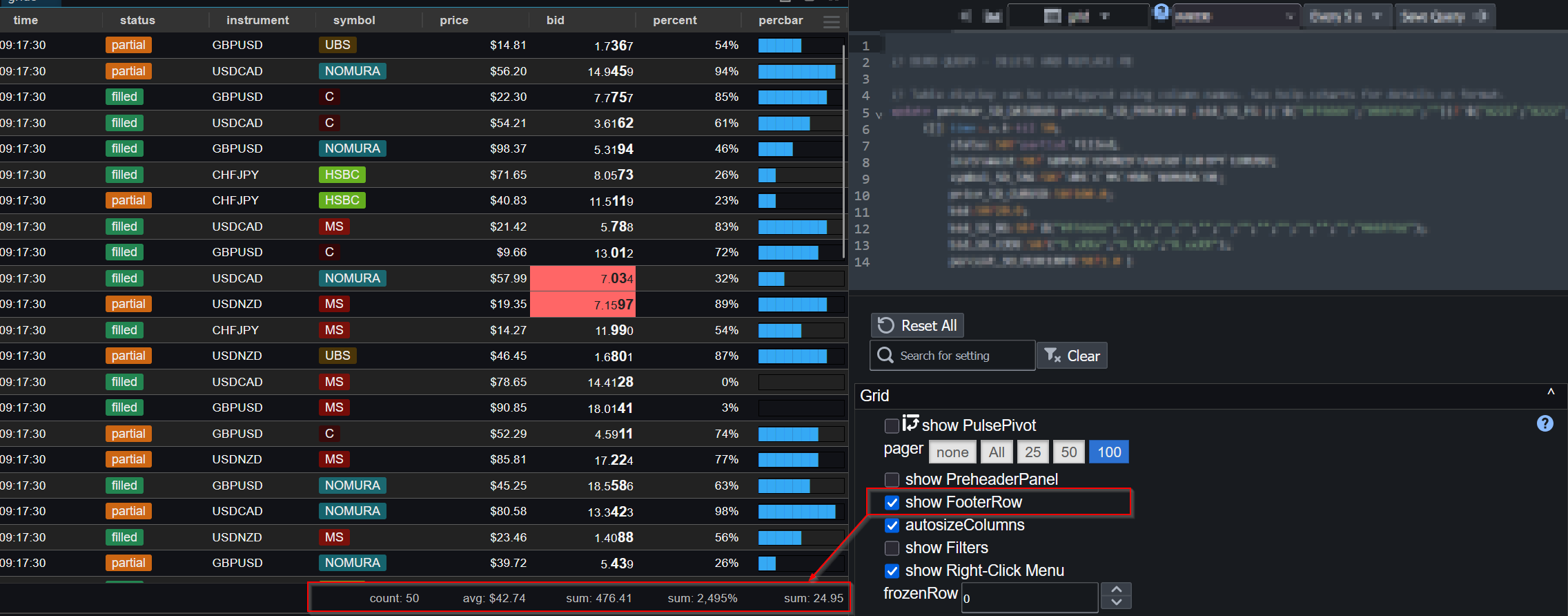
Table Footers
You can now add table footers that show aggregated views of the data including average, count and sum.
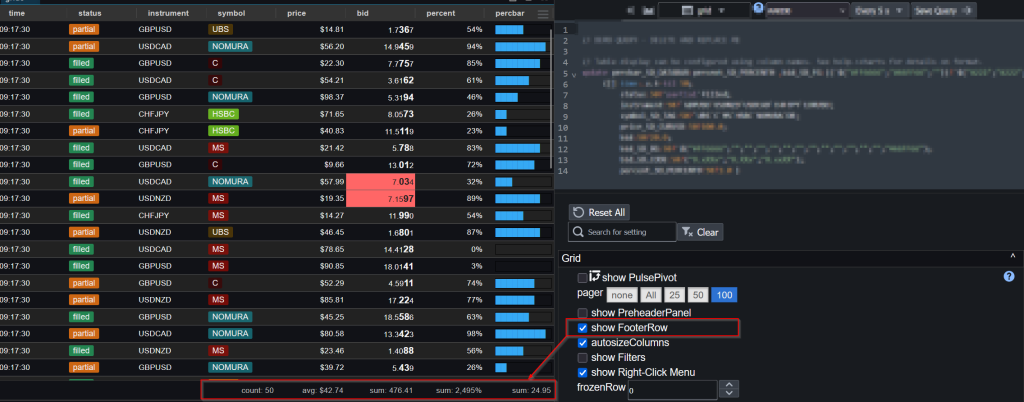
The aggregation function for a given column can be chosen within the column specific configuration:
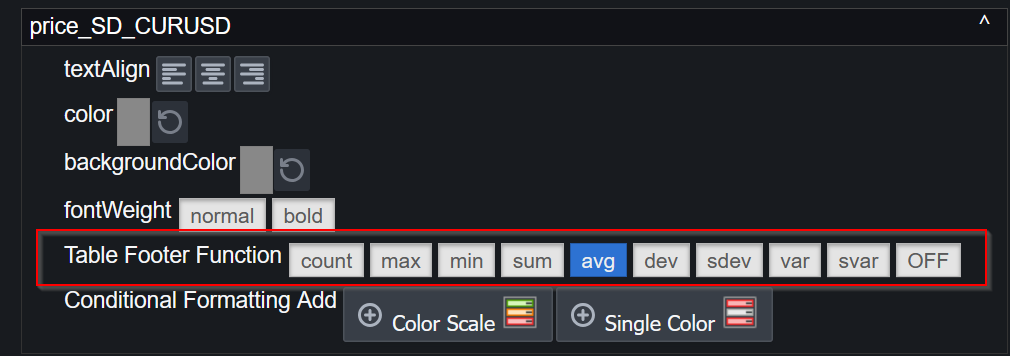
Column Statistics
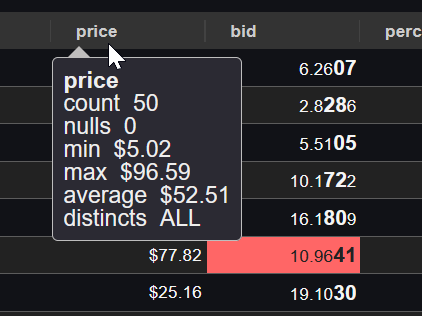
Allow users to get an overview of the data in one column. How many unique values does it contain, nulls, minimum, maximum etc.
Other additions include:
November 23rd, 2025 by admin
QStudio 4.15 Released today with new “Find All” – Press Control+Shift+F to activate.
Download Now.
Thanks to JPArmstrong for the idea.
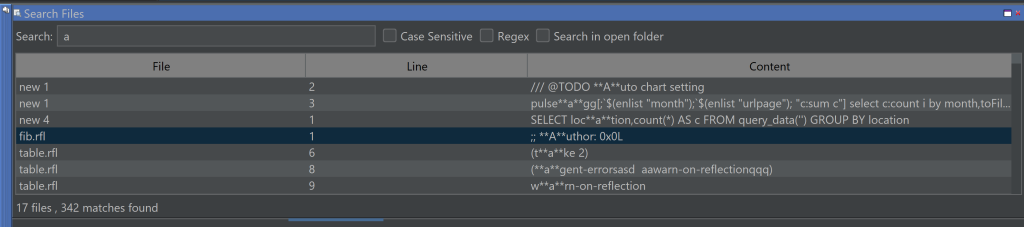
Added highlighting support for python, closure, jflex, rfl, javascript, scala, xpath.
September 15th, 2025 by admin
Pulse 3.25 released with Conditional formatting, a new form creator and new date picker widgets:
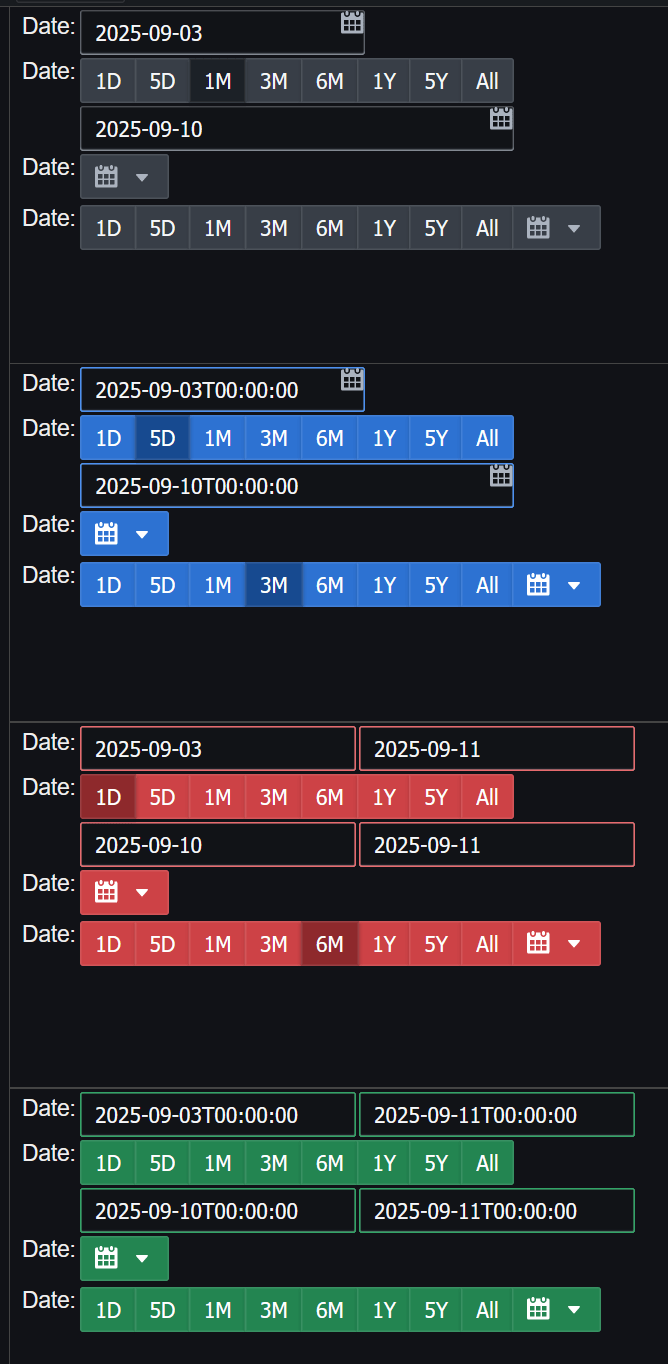
- 2025-09-13 – 3.25 – Enable User Customization.
- Add burger menu that allows end user chart and table customization (user Control option?).
- Add conditional formatting to right-click context menu.
- Tags support multiples.
- SQL Notebooks – Add copy to clipboard to code displays.
- Add Clickable SD_LINK columns in tables help.
- Connection Scalability – Improve JDBC connection pool settings for large 100+ user deploys.
- 2025-09-10 – 3.24 – Improvements to Forms
- Forms – Form editor now supports multi-column drag-and-drop.
- Add Icon support to buttons and text inputs.
- Select multi-dropdown supports select
__ALL__ for when there are lots of options.
- Add intent and size support to all controls.
- Checkbox and Radio support segmented style.
- Improved date pickers help.
- Change default to 30 min refresh.
- Add ability to delete variables in debug UI.
- bugfix: Select multi-dropdown no longer scrolls to top on selection.
- bugfix: Non-editors shown some editor controls when receiving URL.
- bugfix: SQL Notebooks – Fix show queries button.
September 4th, 2025 by admin
- We previously wrote an article on: Kdb+ Acquired by Private Equity
- In July KX was acquired by TA and went private.
- Today 2025-09-04 we are hearing that 100 plus staff may have been let go.What does this mean for KX next?
Update 2025-09-13 – Number being reported is closer to 200.
Update 2025-09-15 – KX and onemarketdata (onetick) have merged.
https://kx.com/news-room/kx-and-onetick-merge-to-unite-capital-markets-data-analytics-ai-and-surveillance-on-one-platform/
May 12th, 2025 by admin
QStudio 4.09 introduces a number of new features to make exploring data easier than ever.
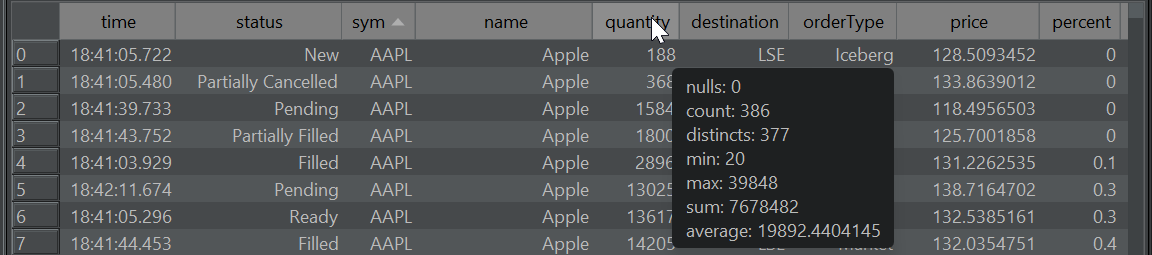
Column Stats
Allows getting a count of nulls, averages and how many distinct values a column contains by hovering the column header:
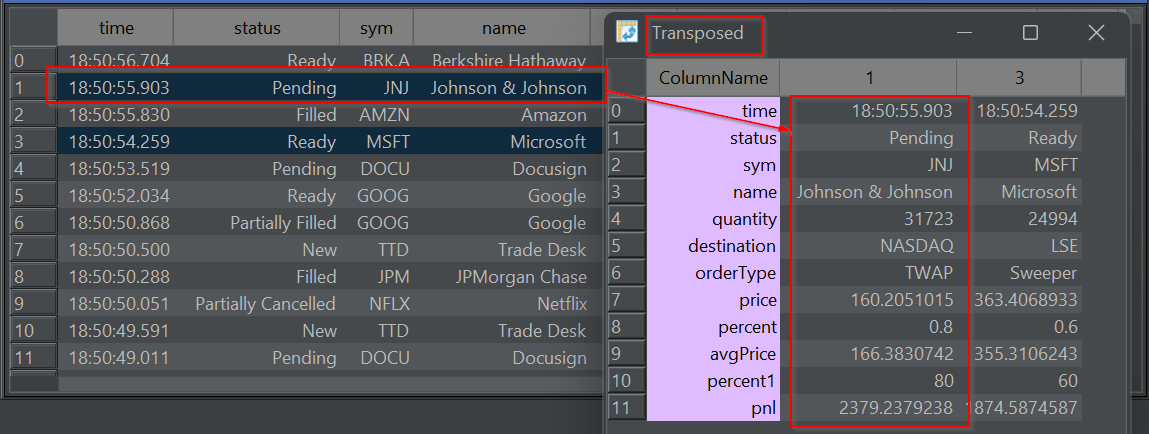
Transposed row(s)
Have a very wide table? Want to quickly see all the column?
Transpose from a row to column based layout for those rows. Allowing you to quickly see all values:
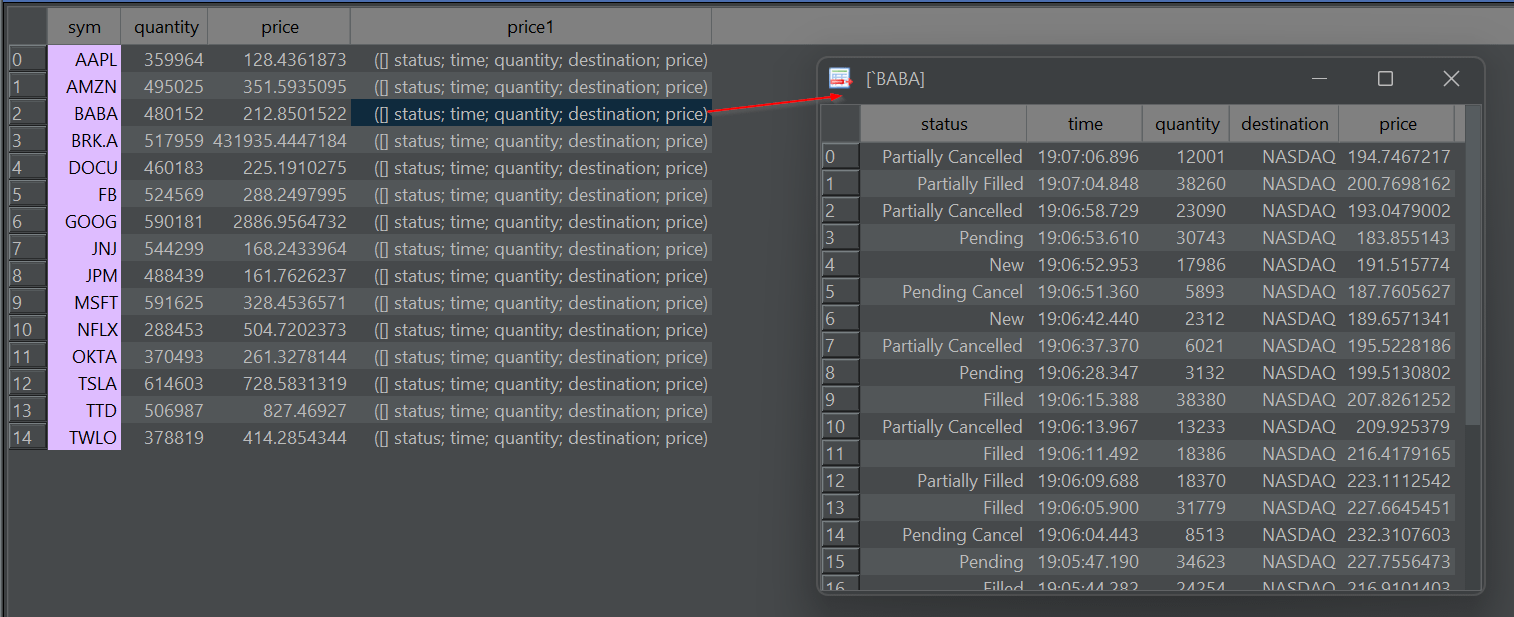
Dive-into Nested Results
Double-click on a nested array or kdb structure (table/dict) to pop-out a table showing only the nested item. You can repeat this to dig deeper and deeper into nested data. (Thanks to Oleg/QPad on pioneering this idea).
As well as these new features, a large number of bugs were fixed:
- 4K Monitor support was significantly improved. You have the option to scale the full UI in preferences.
- Apple Mac got a dedicated release and custom App download.
- We upgraded kdb+ c/jdbc.java to allow SSL TLS.
Full Release Info:
All past release changes can be found here.
2025-05-12 – 4.09 – Improve Autocomplete suggestions
– Add namespace listing panel.
– Improve QDoc to add file level details.
2025-04-22 – 4.08 – Bugfix: Candlestick charts were wrong as receiving wrong timezone from kdb driver. Timezone now set to UTC.
– Bugfix: “Save as” to .sql was shrinking text. Now fixed.
– Bugfix: Show red X close on every document tab.
2025-04-06 – 4.07 – Add UI Scaling and Font size as separate options to help with 4K monitors
– Bugfix: Kdb+ Queries with errors could cause 30 second freezes.
– Bugfix: Switch back to MonoSpaced font. Variable width fonts cause wrong caret position.
– Improved high resolution QStudio icon.
– Mac: Bugfix: Prefences dialog fixed and allows choosing font.
– Mac: Fixed Menu shoing about/preferences/exit.
– Mac: Allow Command+Option+E to run current query.
– 4K handling improved sizing of dialogs.
– Bugfix: Improved duckdb init when folder is empty.
2025-03-13 – 4.06 – Add ability to transpose rows.
– DuckDB 1.2.1. Improve display of DuckDB arrays.
– Add comma separator for thousands option.
2025-02-23 – 4.05 – Upgrade kdb+ c/jdbc.java to allow SSL TLS.
– Add preference to allow hiding all tooltips.
– Double-click on kdb+ table with dictionary/table/list nested in cell will pop it out.
2025-01-23 – 4.04 – Show column info (avg/min/max) when column header is hovered.
– Remove watched expressions entirely.
– Improved UI threading for tree/chart display.