What is a Column-Oriented Database
Increasingly businesses are realizing a one size fits all isn't working for databases. When you want to analyse terabytes of data, with analytical queries that span 1000's of rows, column-oriented databases can provide a 100x speedup. Particularly for time-series data, column-oriented databases have been successfully used to deliver fast storage and analysis.
What is a column-oriented database?

A column-oriented database stores each column continuously. i.e. on disk or in-memory each column on the left will be stored in sequential blocks.
For analytical queries that perform aggregate operations over a small number of columns retrieving data in this format is extremely fast. As PC storage is optimized for block access, by storing the data beside each other we exploit locality of reference. On hard disk drives this is partiularly important which due to their performance characteristics provide optimal performace for sequential access.
Why columns not rows?
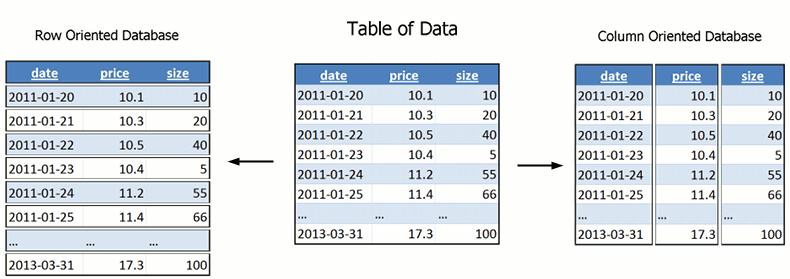
Look at the above image, now imagine which areas need read when you perform a query like "average price" for all dates. In row-oriented databases we have to read over large areas, in column-oriented databases the prices are stored as one sequential region and we can read just that region. Column-oriented databases are therefore extremely quick at aggregate queries (sum, average, min, max, etc.).
Why are most databases row-oriented? I hear you ask. Imagine we want to add one row somewhere in the middle of our data for 2011-02-26, on the row oriented database no problem, column oriented we will have to move almost all the data! Lucky since we mostly deal with time series new data only appends to the end of our table.
Column-Oriented Database vs Row Oriented Database
| Operation | Column-Oriented Database | Row-Oriented Database |
|---|---|---|
| Aggregate Calulation of Single Column e.g. sum(price) | fast | slow |
| Compression | Higher. As stores similar data together | - |
| Retrieval of a few columns from a table with many columns | Faster | has to skip over unnecessary data |
| Insertion/Updating of single new record | Slow | Fast |
| Retrieval of a single record | Slow | Fast |