Archive Page 8
February 27th, 2017 by Ryan Hamilton
qUnit has added a new HTML report to allow visually easily seeing the difference between expected kdb results and actual results. To generate a report you could call:
.qunit.generateReport[.qunit.runTests[]; `:html/qunit.html]
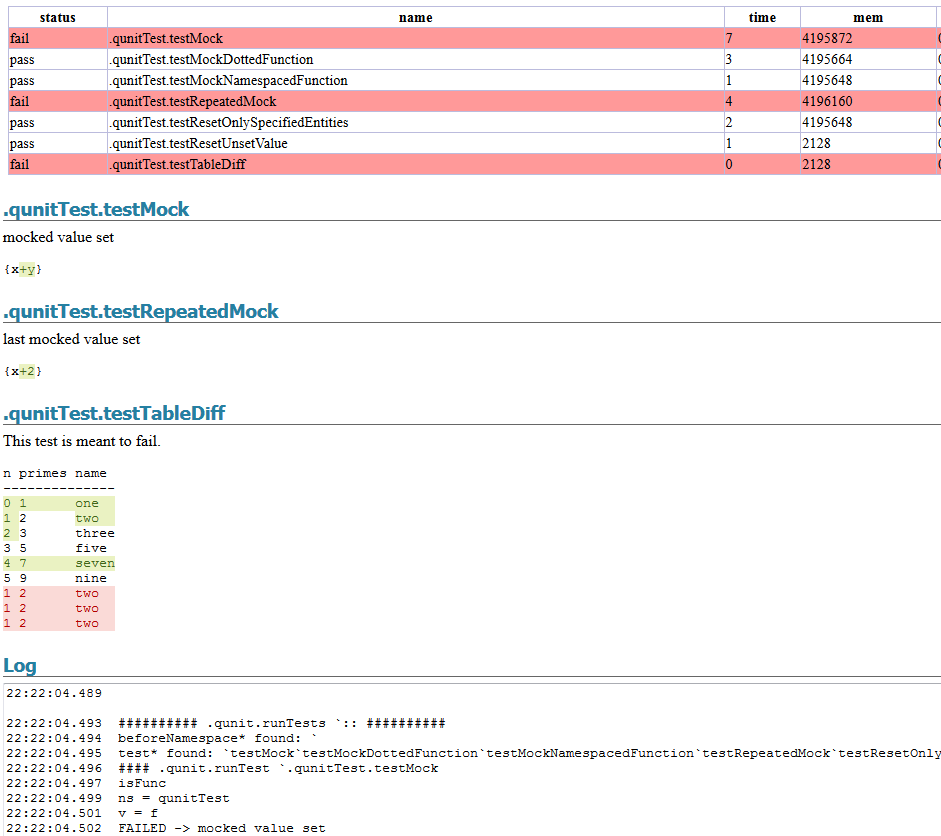
It’s also added a
.qunit.assertKnown[actualResult; expectedFilename; msg]
call to allow comparing an actual results to a file on disk. While allow easy updating of that file and avoiding naming collisions.
February 7th, 2017 by Ryan Hamilton
Download the latest qStudio now.
qStudio Improvements
- Bugfix Sending empty query would cause qStudio to get into bad state.
- Default to chart NoRedraw when first loaded to save memory/time.
- Preferences Improvements
- Option to allow saving Document with windows \r\n or linux \n line endings. Settings -> Preferences… -> Misc
- Allow specifying regex for folders that should be ignored by the “File Tree” window and Autocomplete
- Add copy “hopen `:currentServer” command button to toolbar.
- Ctrl+p Shortcut – Allow opening folders in explorer aswell as files.
- Smarter Background Documents Saving (30 seconds between saves on background thread)
sqlDashboards Improvements
- Allow saving .das without username/password to allow sharing. Prompt user on file open if cant connect to server.
- Bugfix: Allow resizing of windows within sqlDashboards even when “No table returned” or query contains error.
- If query is wrong and missing arg or something, report the reason.
- Stop wrapping JDBC queries as we dont want kdb to use the standard SQL handler. We want to use the q) handler.
February 7th, 2017 by admin
This post is a walkthrough of my implementation in Q of the RosettaCode task ‘Death Star’.
The code is organized as general-purpose bitmap generator which can be used in other projects, and a client specific to the task of deathstar-drawing. The interface is a function which passes a map of pixel position to pixel value. The map can be a mapping function, or alternatively a 2D array of pixel values. The bitmap generator raster-scans the image, getting pixel values from either a mapping function or a mapped array.
genheader follows directly from the referenced BMP Wikipedia article.
genbitmap and genrow perform a raster scan of the image to be constructed. genbitmap steps along the vertical axis, calling genrow, which steps along the pixels of the current line, in turn calling fcn, the pixel-mapping function passed in by the client.
A sample client is included in comments, the simplest possible demonstration of shape and color (a circular mask selecting between two fill colors):
Conveniently, functions and arrays can be equivalently accessed in Q.
Here is an array-passing client which replicates the first example in the Wikipedia article on BMP format.
Element ordering can be confusing at first glance: Byte order for RGB pixels is B,G,R. Also, rows are indexed from bottom to top, and since bitmaps are in row-major order, the first and second array indices designated x and y correspond to the y and x image axes respectively.

After centering the image fcn applies several masks:
is calculates the orientation of a point on a sphere, and then a pixel value for that point, using the dot product of l, the light source direction, and s, the surface orientation. A correction of (1+value)/2 is applied, to achieve the ‘soft’ appearance of a space object in a movie. Alternatively we might have suppressed negative illumination values, to get the high-contrast appearance of an actual space object.
We might want to generate images of the death star at different rotations, however due to some simplifying assumptions we can’t rotate the weapon face to the side without glitching. We calculate z1 and z2 to select between the forward surface of the death star and the rearward surface of the weapon face. We should also calculate z3, the forward surface of the weapon face sphere, and z4, the rearward surface of the death star:
z3:170+z[x2;y;r];
z4:-z1;
Then the masks can be modified so that when z3 > z1 > z4 > z2, an additional bit of background is visible through the carved-out chunk of the deathstar.
TODO: discuss limitations of mask-and-fill; alternative approaches; display-list; …
TODO: discuss animation; …
TODO: discuss three-component architecture: orchestrator, world, bitmap generator
TODO: … conclusions
July 19th, 2016 by admin
I often get asked what open source alternatives are there to kdb+. The answer depends on what you are trying to do. IF there was a product XYZ that provided some similar features, whether it can replace kdb depends on a few issues:
>>”What will XYZ bring us that kdb doesn’t?”
Kdb has been tried and tested over many computer/man-years. The KX team have fixed 1000’s of edge cases, optimization issues and OS specific bugs. Any similar system would have to replicate a lot of that work. Possible but it would take time and teams actually using it. It would also require a corporate entity to provide support and bug fixes together with long term guarantees of availability (not a few part-time committers on github). Ontop of that it would need to deliver more value to make it worth switching.
Kdb is both a database and a programming language and it’s that combination which I believe gives kdb it’s unique power:
– There is no open source database that provides the speed kdb provides for the particular queries suited to finance.
– Combining kdb and basing queries on q-sql/ordered lists (rather than set theory for standard sql) means queries require fewer lines of code. I believe this expressiveness combined with longer term use of kdb/q changes how you think and allows easily forming queries which many people couldn’t begin to write in standard sql.
– However as much as I think q is a selling point of kdb, I know many others would disagree. It takes a reasonable period of time to convince someone non-standard SQL is beneficial.
What is your use case? e.g. Example Queries to Consider:
1. Select top N by category
http://stackoverflow.com/questions/176964/select-top-10-records-for-each-category
select n#price by sym from trade
2. Joining Records on nearest date time:
http://www.bigresource.com/MS_SQL-joining-records-by-nearest-datetime-XsKMeH3t.html
aj[`sym`time;select .. from trade where ..;select .. from quote]
3. Queries dependent on order. (eg price change, subtract row from previous)
http://stackoverflow.com/questions/919136/subtracting-one-row-of-data-from-another-in-sql
select price-prev price from trade....
XYZ would need to support these queries well. Why would I chose XYZ instead of Python/R/J/A+?
Existing (some similar languages) that offer a larger existing user base, more libraries and a proven/stable platform. Unless a way is found to leverage existing languages/libraries XYZ will be competiting for attention against kdb and also python/numpy/julia etc.
>>”bring in the cost factor and should XYZ be considered as a big future player?”
For the target market of kdb the cost is often not the most significant factor in the decision. If kdb can answer questions that other platforms can’t or in a much shorter time, it often adds enough value to make the cost irrelevant. In fact many large firms are happy paying a pricey support agreement for free open source software so that they have someone to (blame) call to resolve an issue quickly.
>>”but could XYZ catch up and begin to be trusted by bigger institutions?”
If XYZ started to be able to answer the three example queries shown above at a reasonable speed multiple perhaps but I consider it unlikely. Kdb is entrenched and for its target use case it is currently unbeatable. Some people may have use cases that don’t need the full power of database and language combined or have other important factors (cost,existing expertise). I think those use cases have viable open source solutions.
June 25th, 2016 by Ryan Hamilton
qStudio 1.41 is now available to download.
It adds the ability to use custom Security Authentications and custom JDBC drivers.
By automatically loading .jar plugins from libs folder.
After a few users reported issues around “watched expressions” we are removing the ctrl+w shortcut as it was often getting used by mistake. The last change was some internal work to improved startup/shutdown logging for debugging purposes..
April 26th, 2016 by Ryan Hamilton

Recently there was a post on SQL tips by the JOOQ guys. I love their work but I think standard SQL is not the solution to many of these problems. What we need is something new or in this case old, that is built for such queries. What do I mean, well let’s look through their examples reimplemented in qsql and I’ll show you how much shorter and simpler this could be.
Everything is a table
In kdb we take this a step further and make tables standard variables, no special notation/treatment, it’s a variable like any other variable in your programming language. Instead of messing about with value()() we define a concise notation to define our variables like so:
Data Generation with Recursive SQL
This is the example syntax they have used to define two tables and then join them:
What to hell! If I want variables, let’s have proper variables NOT “Common Table Expressions”.
I created two tables a and b then I joined them sideways. See how simple that was.
Running Total Calculations
Oh dear SQL how badly you have chosen your examples. Running calculations are to APL/qSQL as singing is to Tom Jones, we do it everyday all day and we like it. In fact the example doesn’t even give the full code. See this SO post for how these things get implemented. e.g. Standard SQL Running Sum
qSQL table Definition and Running Sum:
Finding the Length of a Series
This is their code:
This is KDB:
In 1974 Ken Iverson gave a talk on APL. He described how he reduced it down to a core set of operations that everything could be made from. Using these simple building blocks you could make some really cool things. It’s sad to think we may not have came that far.
qSQL/kdb is a database based on the concept of ordered lists, carrying over many ideas from APL that make array operations shorter and simpler. If you like what you see we provide tutorials on kdb to get started, this intro is a good place to get started.
We also have free online kdb training for students.
February 24th, 2016 by admin
First, in case you haven’t heard about it kdb has a standard SQL mode, you can send queries prefixed with s) and they will be interpreted as standard SQL like so:
Notice how the standard “and” syntax worked when I used s) but without it, q’s right to left evaluation causes problems. It’s about now that a lot of people get very excited, they think great I can skip learning that q-sql and use my standard SQL. Sometimes the look of joy on their faces transforms to frustration once they start using it. So let’s look at what works:
| Operation |
Works? |
| Standard SQL Inserts |
Yes |
| ORDER BY |
half works |
| COUNT |
Yes |
| DELETE |
Yes |
| UPDATE |
Yes |
| String matching |
slightly works |
| NOT |
NO |
| IN |
Yes |
| GROUP BY |
Yes |
| LIMIT / TOP |
NO |
| Date Times |
NO |
Standard SQL Inserts work
ORDER BY half works
“ORDER BY” will sort the columns in ascending order, attempting to use DESC has no effect.
COUNT works
DELETE works
UPDATE works
String matching slightly works
NOT fails
Modifying our String query slightly by adding NOT throws an error. My guess is that the interpreter has got confused.
IN works
GROUP BY works
LIMIT / TOP does not work
Date Times Don’t Work Right
Overall standard SQL support in kdb has got much better. However I would still recommend only using the s) syntax for plugging into an existing jdbc/odbc visualization tool and getting some immediate simple results. For any form of complex queries on strings, joins etc. support is either not there or the result may not be what you expect.
February 15th, 2016 by admin
qStudio 1.40 is now available to download.
The latest changes include:
- No need to save changes before shutdown, unsaved changes stored till reopened.
- Add sqlchart to system path.
- Fix display of tables with underscore in the name.
- Database documenter/report enhancements
- Improved code printing
- FileTreePanel much more efficient at displaying large number of files.
November 16th, 2015 by Ryan Hamilton
Julia programming language is being touted as the next big thing in scientific programming. It’s high-level like R/Python but meant to be much faster due to its smart compiler. I’ve been giving it a bit of a tryout, as part of learning it I’ve generated a list of all julia functions and will be creating examples for some of the more popular ones.
November 5th, 2015 by John Dempster
Previously on our blog we had a lively debate about a possibly Open Sourced kdb+ , unfortunately kx now seems to be moving the opposite direction. In a recent announcement they are now restricting “32-bit kdb+ for non-commercial use only”. The timing is particularly unfortunate as:
Alternative (far less enterprise proven) solutions are available:
- MAN AHL have released Arctic an open source Market Data platform based on python and MongoDB
- Kerf Database – A DB aimed at the same market as kdb has now partnered with Briarcliff-Hall and is making greater sales inroads
This renewed interest in kdb alternatives hasn’t so far delivered a kdb+ killer but I fear in time it will.