2024 has been a good year with new major versions of both QStudio and Pulse released. 1000s of new users using our tools and we continue to release regularly and keep improving. Thanks go to our users for raising issues, providing feedback and commercially backing us.
Want to create beautiful live updating SQL notebooks?
While being able to easily source control the code?
and take static snapshots to share with colleagues that don’t have database access?
Today we launched exactly what you need and it’s available in both:
QStudio Version 4 – Desktop SQL Client entirely based on editing markdown files locally.
Pulse Version 3 – As a shared team server, where users only need a web address to get started and share results.
SQL Notebook Examples
We have worked with leading members of the community to create a showcase of examples.
These are snapshotted versions with static data. The source markdown and most the data to recreate them are available on github.
Let us know what you think, please report any issues, feature suggestions or bugs on our github QStudio issue or Pulse issue tracker.
Thanks to everyone that made this possible. Particularly Brian Luft, Rich Brown, Javier Ramirez, Alexander Unterrainer, Mark Street, James Galligan, Sean Keevey, Kevin Smyth, KX, Nick Psaris and QuestDB.
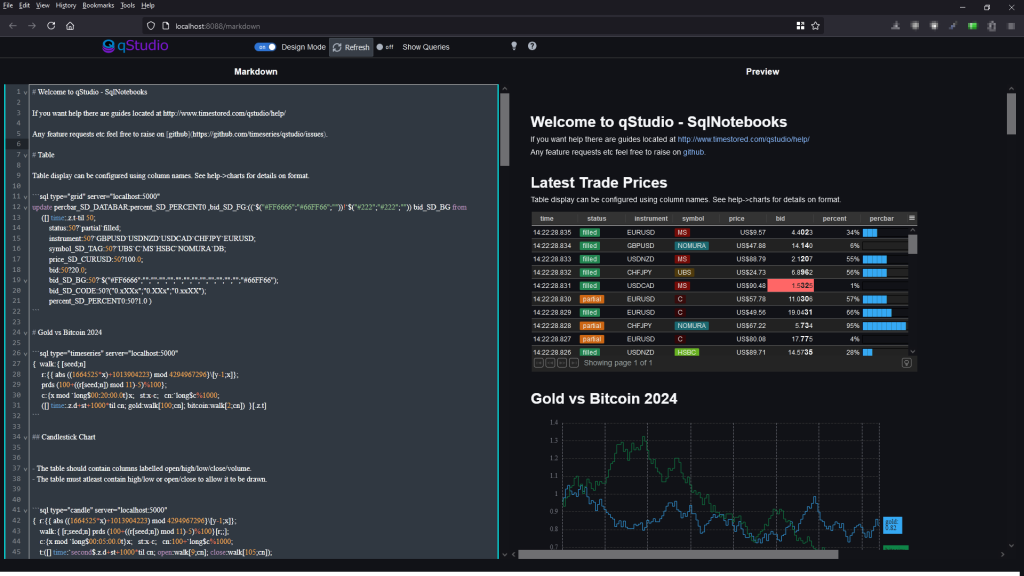
SQL+Markdown qStudio experiment 🚀 🚀 Quick report creation with nice git code commits.
If this is something that interests you, message me.
Particularly if you have tried other notebooks and hold strong opinions 😡 .
At TimeStored we are constantly running experiments with both Pulse and qStudio with small groups of users to see what new ideas may provide value. Most fail. They don’t always work out or they don’t gather enough interest to be viable but we think SQLMarkdown might be a winner. We are already finding it useful for our own workflows.
It’s approaching 2 years since we launched Pulse and it’s a privilege to continue to listen to users and improve the tool to deliver more for them. A massive thanks to everyone that has joined us on the journey. This includes our free users, who have provided a huge amount of feedback. We are commited to maintaining a free version forever.
We want to keep moving at speed to enable you to build the best data applications.
Below are some features we have added recently.
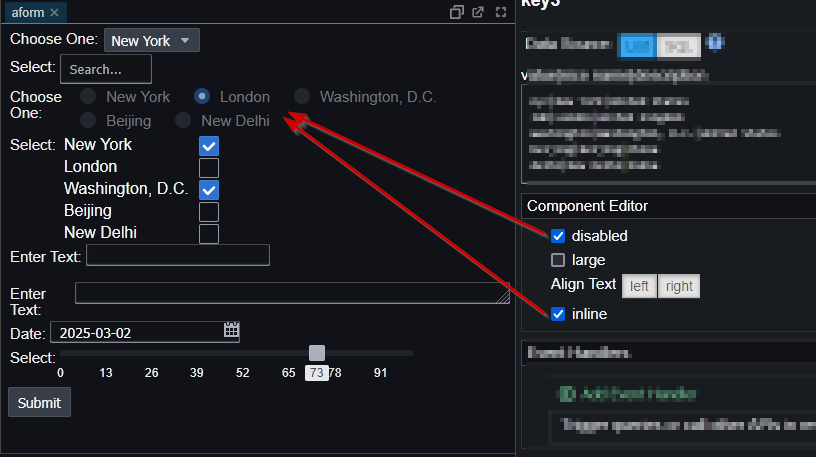
Pulse enables authors to simply write a select query, then choose columns for group-by, pivot and aggregation. Users can then change the pivoted columns to get different views of the data. The really technical cool part is:
Unlike other platforms, Pulse does not attempt to pull back all data.
All aggregation of data is performed on the SQL server, making it really fast.
For kdb+, aggregation and pivoting occur on the kdb+ end using the common piv function.
As we have deployed Pulse at larger firms with more users, the backend databases began to become a bottleneck.
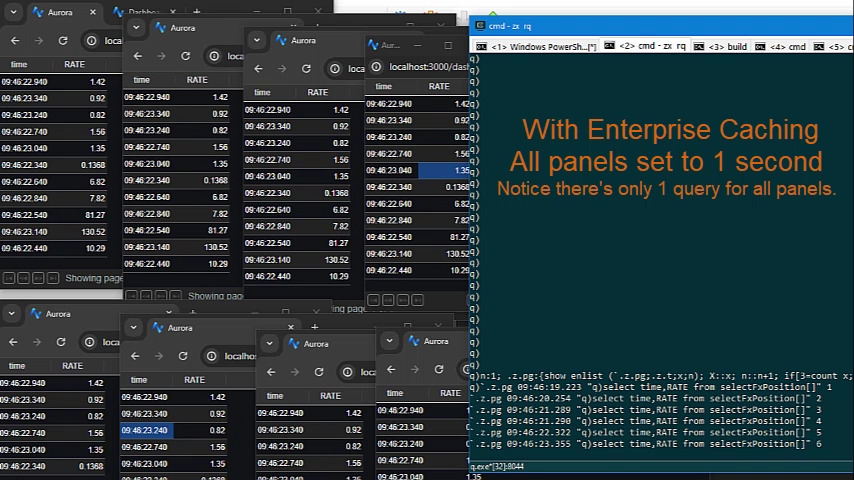
Polling queries to data sources can now be cached and results reused within the time intervals selected.
This means whether there are 1, 10 or 100 users looking at the same dashboard with the same variables, it will only query once, not separately for every user.
We just launched a new sql documentation website: sqldock.com
to allow integration with Pulse / qStudio and docs more easily.
More updates on this integration will be announced shortly. 🙂
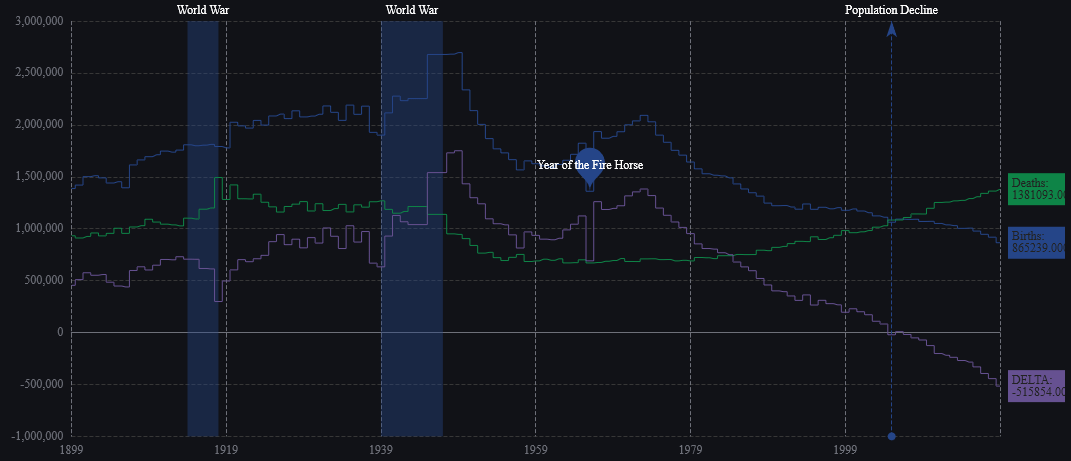
We have been working on version 2.0 of Pulse with a select group of advance users for weeks now. To give you a preview of one new feature, check out markers shown on the chart below. We have marker points, lines and areas.For example this will allow adding a news event to a line showing a stock price. This together with many other changes should be released soon as part of 2.0.
Pulse is specialized for real-time interactive data, as such it needs to be fast, very fast. When we first started building Pulse, we benchmarked all the grid components we could find and found that slick grid was just awesome, 60East did a fantastic writeup on how Slick grid compares to others. As we have added more features, e.g. column formatting, row formatting, sparklines…..it’s important to constantly monitor and test performance. We have:
Automated tests that check the visual output is correct.
Throughput tests to check we can process data fast enough
Manual tests to ensure subtle human interactions work.
Memory leak checks as our dashboards can be very long running.
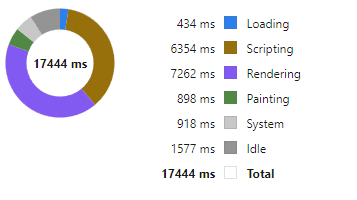
Today I wanted to highlight how our throughput tests work by looking at our grid component.
HTML Table Throughput Testing
To test throughput we:
Use scenarios as close to our customers typical use cases as possible.
The most common query being a medium sized scrolling trade blotters with numerical/date formatting and row highlighting.
200 rows of data, scrolling 50 rows each update.
We use a subscription connection to replay and render 1000s of data points as fast as possible.
Video Demonstrating 21,781 rows being replayed as 435 snapshots taking 16 seconds = 27 Updates per second. (European TV updates at 25 FPS).
Update: After this video we continued making improvements and with a few days more work got to 40 FPS.
Profiling Slick Grid Table
Breakdown
We then examine in detail where time is being spent. For example we:
Turn on/off all formatting, all rendering options.
Add/Remove columns
Change screen sizes
Change whether edit mode is on or table cells have been select (Off fact: selecting a cell makes the grid 30% slower to update)
Then we try to improve it!
Often this is looking at micro optimizations such as reducing the number of objects created. For example the analysis of how to format columns is only performed when columns change not when data is updated with the same schema. The really large wins tend to be optimizing for specific scenarios, e.g. a lot of our data is timestamped and received mostly in order. But those optimization are for a later post.
We want to be the best finance streaming visualization solution. To achieve that, we can’t just use off the shelf parts, we have built our own market data order book visualization component from scratch, it’s only dependency is webgl. We call it DepthMap. It plots price levels over time, with the shading being the amount of liquidity at that level. It’s experimental right now but we are already receiving a lot of great feedback and ideas.
Faster Streaming Data
A lot of our users were capturing crypto data to a database, then polling that database. We want to remove that step so Pulse is faster and simpler. The first step is releasing our Binance Streaming Connection. In addition to our existing kdb streaming connection, we are trialling Websockets and Kafka. If this is something that interests you , please get in touch.
Our latest product Pulse is for displaying real-time interactive data direct from any database. To get most benefit, the underlying databases need to be fast (<200ms queries). For our purposes databases fall into 2 categories:
Really really fast, can handle queries every 200ms or less and seamlessly show data scrolling in
All Other Databases. The 95%+.
It’s very exciting when we find a new database that meets that speed requirement. I went to the website, downloaded QuestDB and ran it. Coming from kdb+ imagine my excitement at seeing this UI:
Good News:
A very tiny download (7MB .jar file)
There’s a free open source version
They are focussed on time-series queries
Did I mention it’s fast
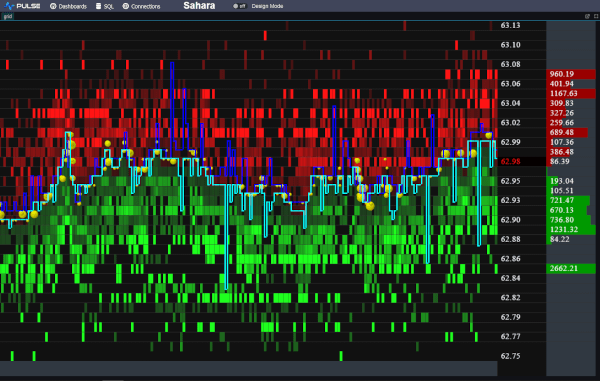
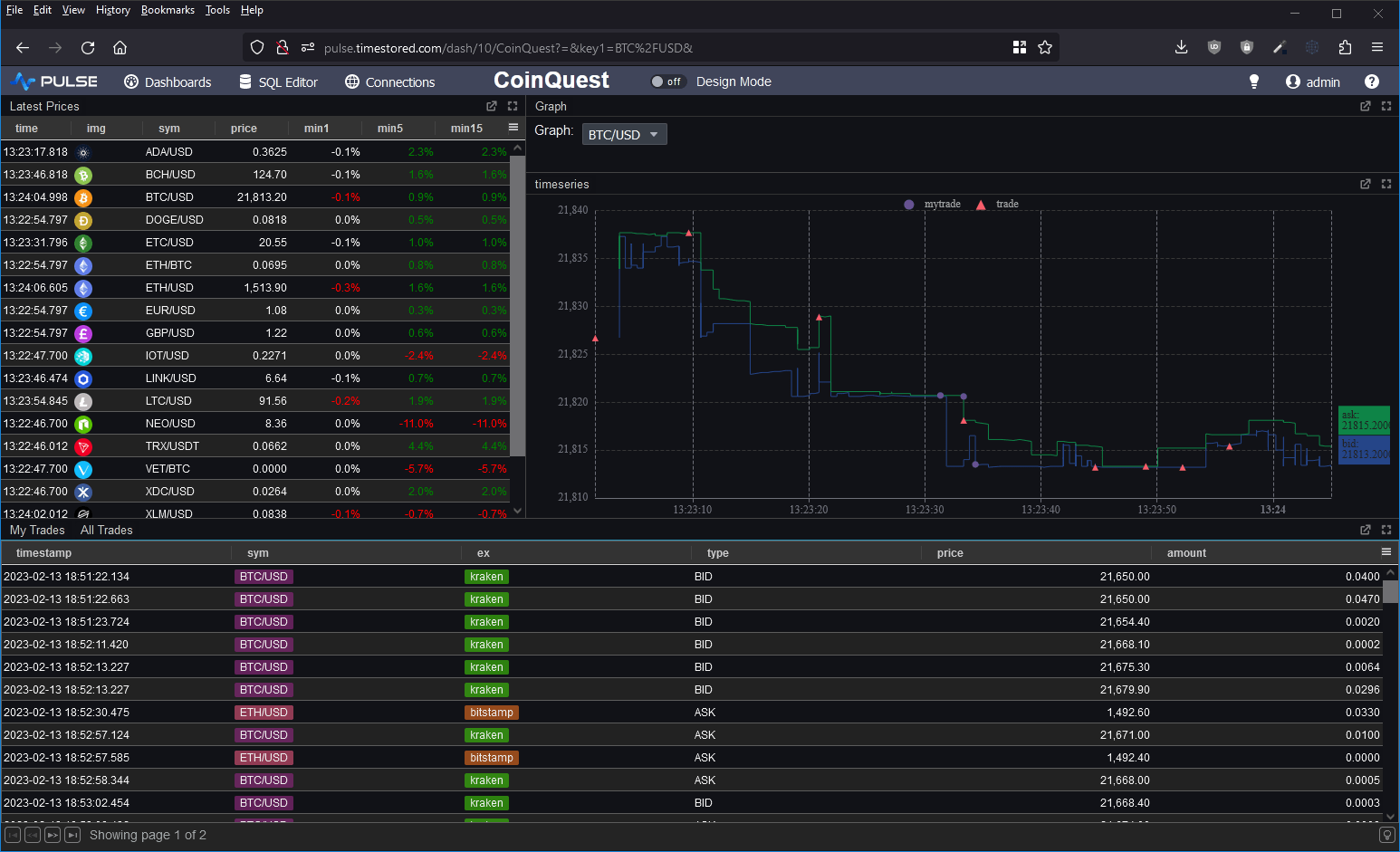
I wanted to take it for a spin and to test the full ingestion->store->query cycle. So I decided to prototype a crypto dashboard. Consume data from various exchanges and produce a dashboard of latest prices, trades and a nice bid/ask graph as shown below.
Good Points
It simply worked.
QuestDB chose to be PostgreSQL wire and query compatible. A great technical choice as:
It will work with many tools including Pulse without complication
Many people already know SQL. I’ve been teaching q/kdb for years and when people learn it, you can use it for absolutely amazing things that standard SQL is terrible at. However most people do not reach that level of expertise. By using standard SQL more people can reuse their existing knowledge.
They then added Time-series specific extensions ontop for querying, including:
“Latest on” – that’s equivalent to kdbs “last by”. It’s used to generate the “latest prices” table in the dashboard with a 1/5/15 minute lag.
QuestDB can automatically create tables when you first send data, there’s no need to send “Create Table …”. This was useful when I was tweaking the data layout from the crypto feeds.
At parts my SQL was rusty and I asked for help on their slack channel. Within an hour I got helpful responses to both questions.
Within a very short time, I managed to get the database populated and the dashboard live running. This is the first in a long time that a database has gotten me excited. It seems these guys are trying to solve the same user problems and ideas that I’ve seen everywhere. There were however some significant feature gaps.
Feature Gaps
No nested arrays. If I want to store bid/asks, I can only currently do it with columns bid1/bid2/bid3, no arbitrary length arrays.
Very limited window analytics. Other than “LATEST ON” QuestDB won’t let me perform analysis within that time window or within arrays in general.
I really missed my
`time xasc (uj/)(table1;table2)
pattern for combining multiple tables into one. For the graph I had to use a lengthy SQL UNION.
In general kdb+ has array types and amazingly lets you use all the same functions that work on columns on nested structures. I missed that power.
No security on connections. It seems security integration will be an enterprise feature.
Open Source Alternative to kdb+ ?
Overall I would say not yet but they seem to be aiming at a similar market and they are moving fast.
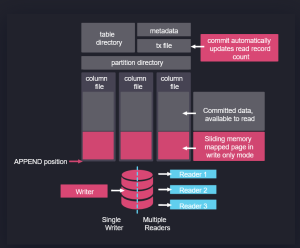
In fact, if you look at their architecture on the right, it’s obvious some of their team have used kdb+. Data is partitioned on date, with a separate folder per table and a column per file. Data is mapped in when read and appended when new data arrives.
In some ways this architecture predates kdb+ and originates from APL. It’s good to see new entrants like QuestDB and apache arrow pick up these ideas, make them their own and take them to new heights. I think kdb+ and q are excellent, I was always frustrated that it has remained niche while inferior technical solutions became massively popular, if QuestDB can take time-series databases and good technical ideas to new audiences, I wish them the best of luck!
Please leave any of your thoughts or comments below as I would love to hear what others think.
If you want to see how to setup QuestDB and a crypto dashboard yourself, we have a video tutorial:





If this is something that interests you, message me.
Particularly if you have tried other notebooks and hold strong opinions 😡 .