Archive for the 'kdb+' Category
April 18th, 2026 by admin
QStudio 5.07 has been released:
January 17th, 2026 by admin
Size Isn’t Everything with Databases – Nor When It Comes to Database Driver size.
With QStudio and Pulse, we get to work hands-on with 30+ databases. That gives us a lot of appreciation for teams that do more with less – especially some of the smaller teams building compact databases and drivers that deliver an outsized amount of value.
In both Pulse and QStudio, we bundle a core set of JDBC drivers and optionally download others when a user adds a specific database. We do this deliberately to keep the applications lightweight. We care about every megabyte and don’t want to bloat either our product or our users’ SSDs.
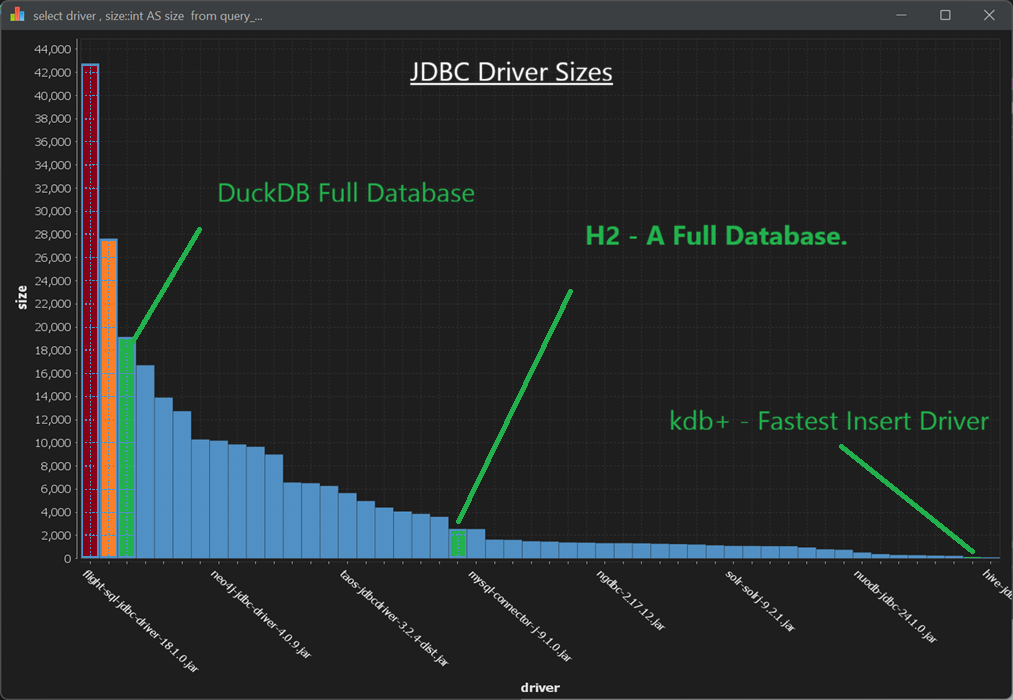
Database Driver Size
Notice:
- DuckDB – An entire database that is smaller than both the Snowflake and the Arrow/flight SQL driver.
- H2 – Another full database (Java-specific) that is smaller than roughly a third of the drivers we ship.
- Kdb+ – Supports JDBC and has the fastest industry wide bulk inserts while being one .java file (1900 lines, 60KB)
Obviously, a smaller driver or database isn’t always “better” in isolation. But having worked closely with these three in production settings, we can say they are exceptional pieces of engineering. The performance these teams achieve with such compact codebases is a testament to strong engineering discipline and a relentless focus on efficiency end-to-end. Huge congratulations to the teams behind them.
Scale matters but Efficiency is what makes scale sustainable.
Database Driver Size
Full Sizes (in KB):
42776 flight-sql-jdbc-driver-18.1.0.jar
27644 snowflake-jdbc-3.13.6.jar
19144 athena-jdbc-3.2.0-with-dependencies.jar
16696 kyuubi-hive-jdbc-shaded-1.7.1.jar
13904 ignite-core-2.15.0.jar
12728 sqlite-jdbc-3.42.0.0.jar
10284 kylin-jdbc-5.0.0-alpha.jar
10180 neo4j-jdbc-driver-4.0.9.jar
9856 trino-jdbc-422.jar
9652 presto-jdbc-0.282.jar
8984 redshift-jdbc42-2.1.0.28.jar
6564 jt400-20.0.0.jar
6504 presto-jdbc-350.jar
6268 mongodb-jdbc-2.0.2-all.jar
5652 taos-jdbcdriver-3.2.4-dist.jar
4964 gemfirexd-client-2.0-BETA.jar
4400 ojdbc8-19.19.0.0.jar
4060 jdbc-1.30.22.3-jar-with-dependencies.jar
3856 omnisci-jdbc-5.10.0.jar
3600 derby-10.15.2.0.jar
2556 h2-2.2.224.jar
2540 mysql-connector-j-9.1.0.jar
1628 hsqldb-2.7.2-jdk8.jar
1608 hsqldb-2.7.2.jar
1488 jdbc-3.00.0.1-jar-with-dependencies.jar
1456 redis-jdbc-driver-1.4.jar
1380 clickhouse-jdbc-0.6.0.jar
1368 jdbc-1.30.22.5-jar-with-dependencies.jar
1324 ngdbc-2.17.12.jar
1324 ngdbc-2.17.10.jar
1308 mssql-jdbc-10.2.1.jre8.jar
1268 avatica-core-1.17.0.jar
1240 clickhouse-jdbc-0.4.6.jar
1204 terajdbc-20.00.00.11.jar
1136 sqream-jdbc-4.5.9.jar
1084 solr-solrj-9.2.1.jar
1080 solr-solrj-9.3.0.jar
1064 postgresql-42.7.4.jar
1060 jdbc-4.50.4.1.jar
952 snappydata-store-client-1.6.7.jar
792 x-pack-sql-jdbc-7.9.1.jar
752 crate-jdbc-2.7.0.jar
516 nuodb-jdbc-24.1.0.jar
380 ucanaccess-5.0.1.jar
300 clickhouse-jdbc-0.2.6.jar
284 taos-jdbcdriver-3.2.1.jar
248 csvjdbc-1.0.40.jar
228 ignite-core-3.0.0-beta1.jar
124 lz4-pure-java-1.8.0.jar
100 hive-jdbc-1.2.1.spark2.jar
December 6th, 2025 by admin
QStudio 5.0 is now Open Source after 13 years of development!
QStudio remains a fast, modern SQL editor supporting over 30 databases including MySQL, PostgreSQL, DuckDB, QuestDB, and kdb+/q. Version 5.0 continues our focus on performance, analytics and extensibility now with an open community behind it.
🎉 QStudio Is Now Open Source
After 13 years of development, QStudio is now fully open source under a permissive license. Developers, data analysts and companies can now contribute features, inspect the code, and build extensions.
Open Source Without the Fine Print.
No enterprise edition. No restrictions. No locked features. QStudio is fully open for personal, professional, and commercial use.
New Features with 5.0
New Table Formatters, Better Visuals, Better Reporting
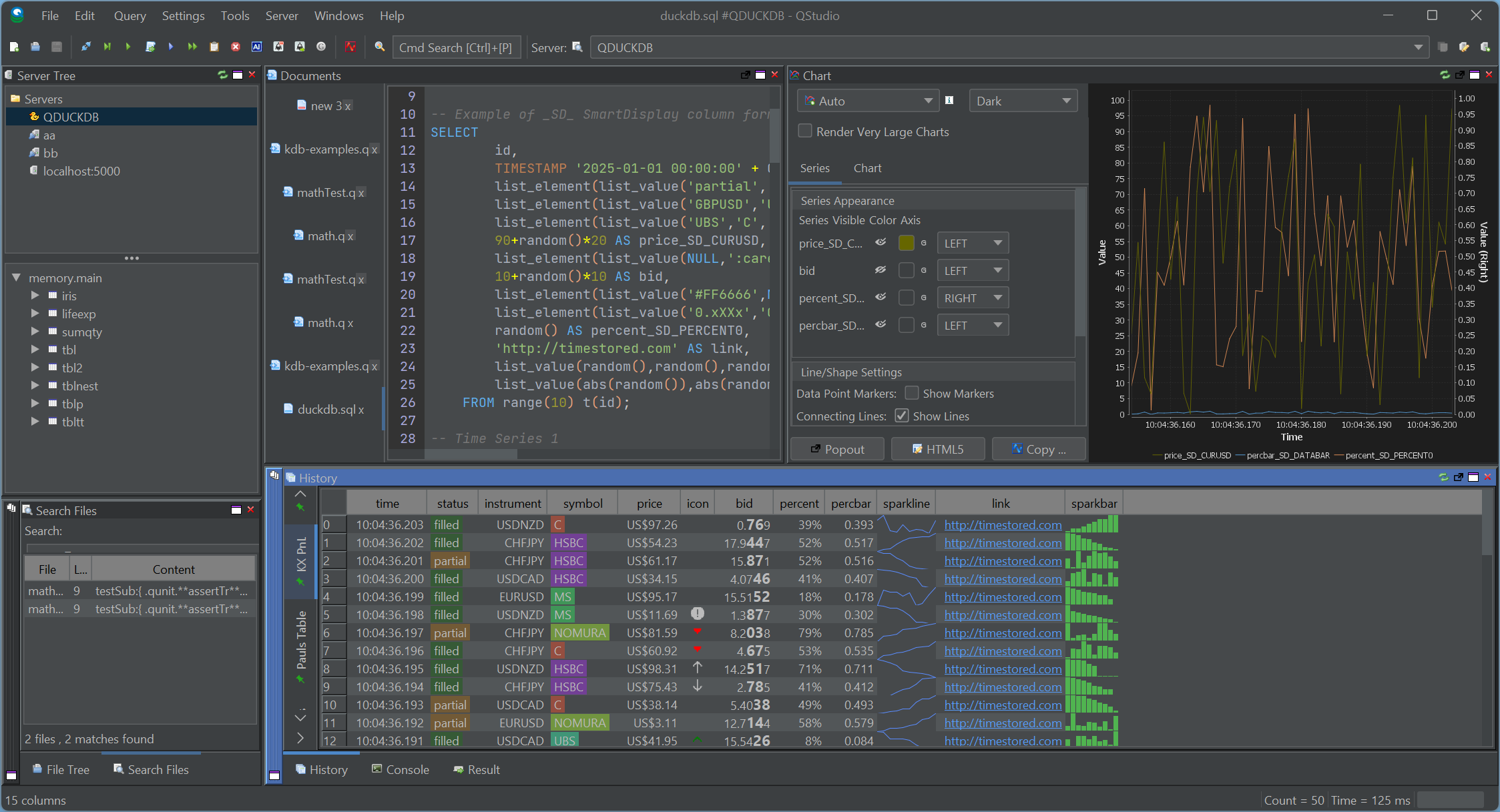
 SmartDisplay is QStudio’s column-based automatic formatting system. By adding simple _SD_* suffixes to column names, you can enable automatic number, percentage, and currency formatting,Sparklines, microcharts and much more. This mirrors the behaviour of the Pulse Web App, but implemented natively for QStudio’s result panel.
SmartDisplay is QStudio’s column-based automatic formatting system. By adding simple _SD_* suffixes to column names, you can enable automatic number, percentage, and currency formatting,Sparklines, microcharts and much more. This mirrors the behaviour of the Pulse Web App, but implemented natively for QStudio’s result panel.
Spark Lines + Micro Charts

Comprehensive Chart Configuration
Fine-tune axes, legends, palettes, gridlines and interactivity directly inside the chart builder.
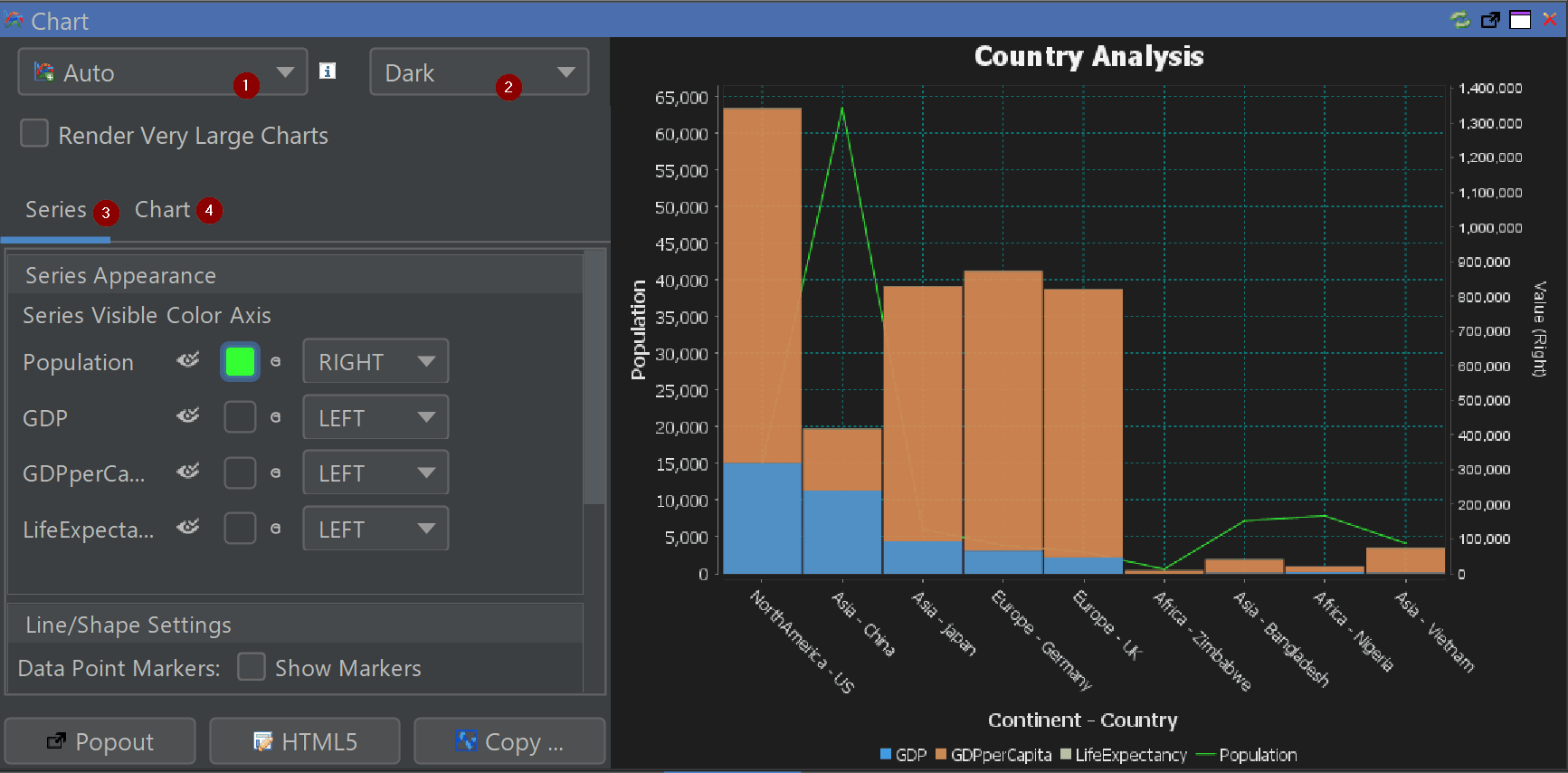
New Chart Themes
Excel, Tableau and PowerBI-inspired styles for faster insight and cleaner dashboards.

Other Major Additions
- Back / Forward Navigation — full browser-like movement between queries.
- Smart Display (SD) — auto-formats tables with min/max shading and type-aware formatting.
- Conditional Formatting — highlight rows or columns based on value rules.
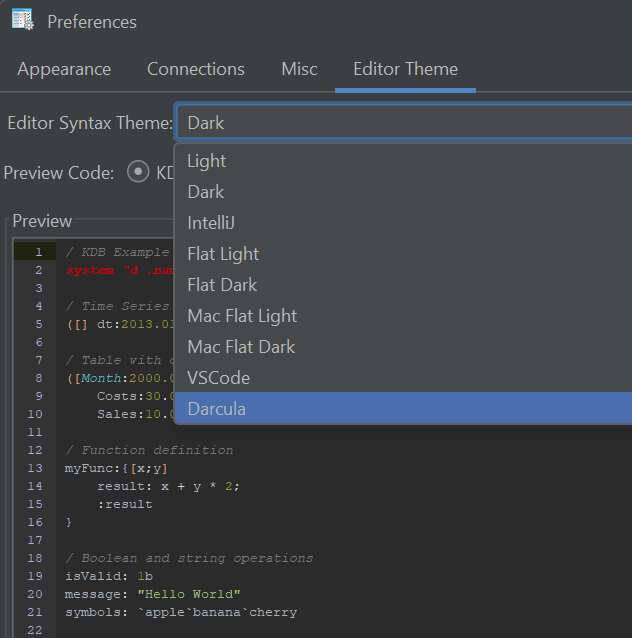
- New Code Editor Themes — dark, light and popular IDE-style themes.
- Extended Syntax Highlighting — Python, Scala, XPath, Clojure, RFL, JFlex and more.
- Improved kdb+/q Support — nested / curried functions now visible and navigable.
- Search All Open Files (Ctrl+Shift+F)
- Navigation Tabs in Query History — with pinning.
- Improved Chinese Translation
- DuckDB Updated to latest engine.
- Hundreds of minor UI and performance improvements
- Legacy Java Removed — cleaner, modern codebase.
Code Editor Improvements
Better auto-complete, themes and tooling for large SQL files.
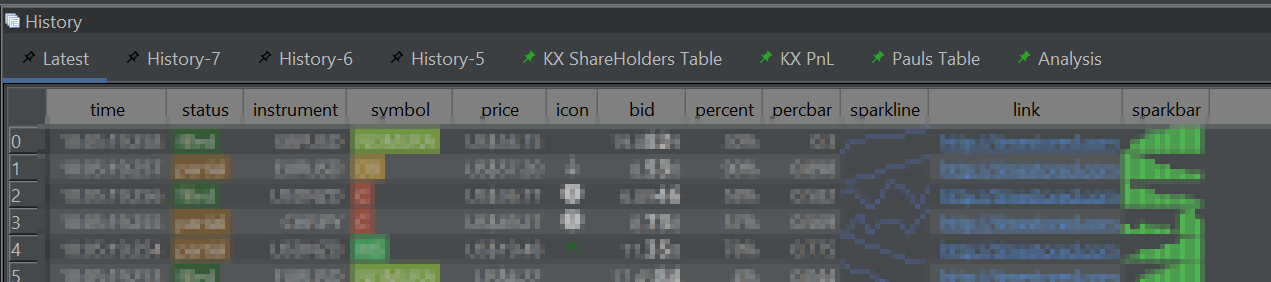
Pinned Results
Pin results within the history pane for later review or comparison.
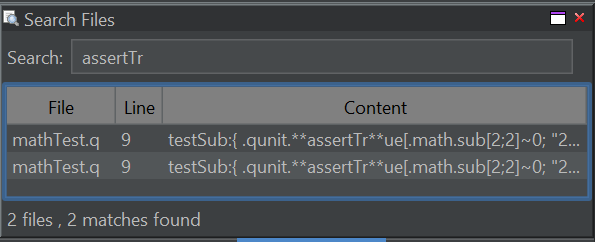
Search Everywhere
Control+Shift+F to search all open files and your currently selected folder.
Our History
- 2013–2024: QStudio provided syntax highlighting, autocomplete, fast CSV/Excel export and cross-database querying.
- Version 2.0: QStudio expands support to 30+ Databases.
- Version 3.0: Introduced DuckDB integration, Pulse-Pivot, Improved export options.
- Version 4.0: Introduced SQL Notebooks and modern visuals.
- Version 5.0: Open Source + hundreds of improvements across charts, editing, navigation and data analysis.
We aim to create the best open SQL editor for analysts and engineers. If you spot a bug or want a feature added, please open an issue
November 23rd, 2025 by admin
QStudio 4.15 Released today with new “Find All” – Press Control+Shift+F to activate.
Download Now.
Thanks to JPArmstrong for the idea.
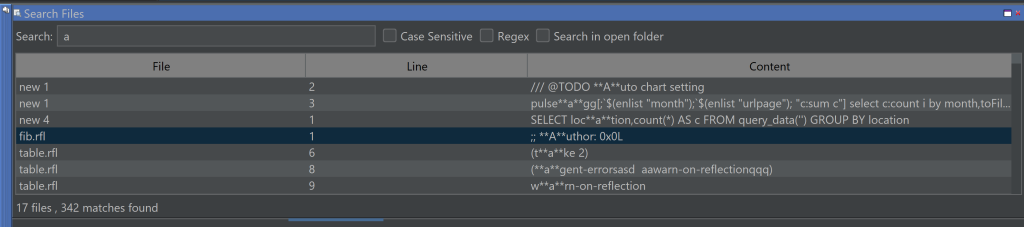
Added highlighting support for python, closure, jflex, rfl, javascript, scala, xpath.
September 15th, 2025 by admin
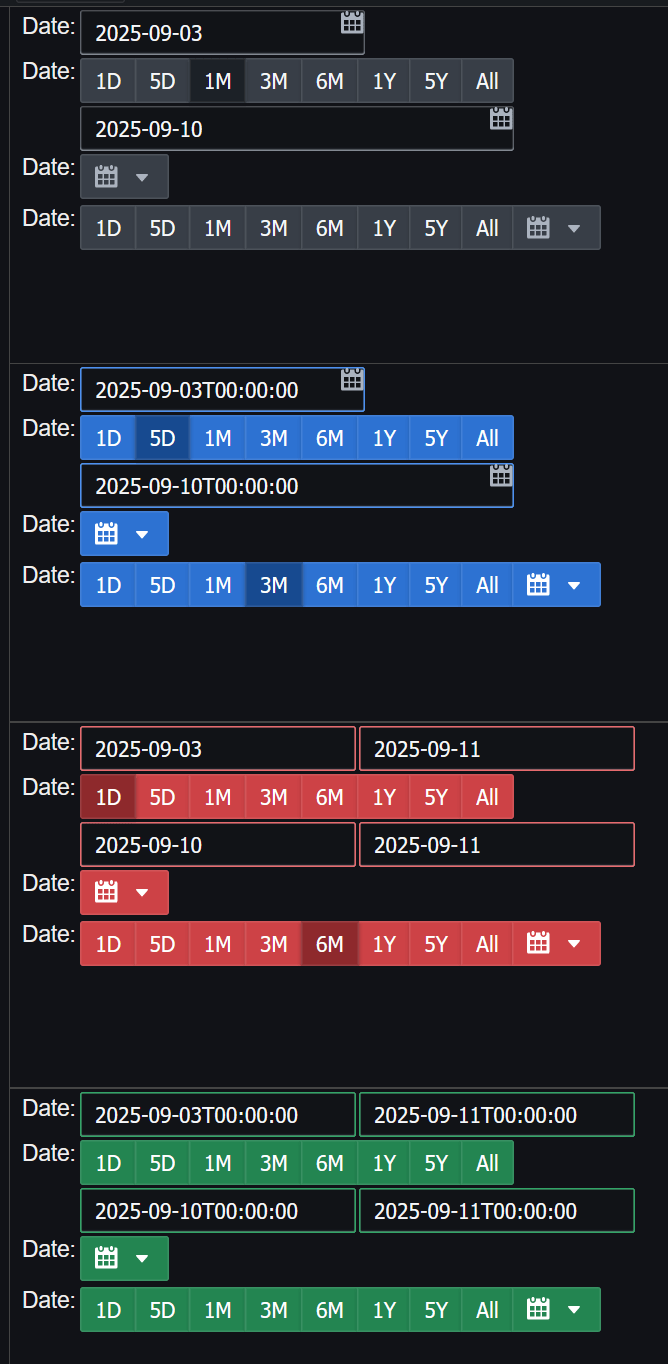
Pulse 3.25 released with Conditional formatting, a new form creator and new date picker widgets:
- 2025-09-13 – 3.25 – Enable User Customization.
- Add burger menu that allows end user chart and table customization (user Control option?).
- Add conditional formatting to right-click context menu.
- Tags support multiples.
- SQL Notebooks – Add copy to clipboard to code displays.
- Add Clickable SD_LINK columns in tables help.
- Connection Scalability – Improve JDBC connection pool settings for large 100+ user deploys.
- 2025-09-10 – 3.24 – Improvements to Forms
- Forms – Form editor now supports multi-column drag-and-drop.
- Add Icon support to buttons and text inputs.
- Select multi-dropdown supports select
__ALL__ for when there are lots of options.
- Add intent and size support to all controls.
- Checkbox and Radio support segmented style.
- Improved date pickers help.
- Change default to 30 min refresh.
- Add ability to delete variables in debug UI.
- bugfix: Select multi-dropdown no longer scrolls to top on selection.
- bugfix: Non-editors shown some editor controls when receiving URL.
- bugfix: SQL Notebooks – Fix show queries button.
September 4th, 2025 by admin
- We previously wrote an article on: Kdb+ Acquired by Private Equity
- In July KX was acquired by TA and went private.
- Today 2025-09-04 we are hearing that 100 plus staff may have been let go.What does this mean for KX next?
Update 2025-09-13 – Number being reported is closer to 200.
Update 2025-09-15 – KX and onemarketdata (onetick) have merged.
https://kx.com/news-room/kx-and-onetick-merge-to-unite-capital-markets-data-analytics-ai-and-surveillance-on-one-platform/
May 12th, 2025 by admin
QStudio 4.09 introduces a number of new features to make exploring data easier than ever.
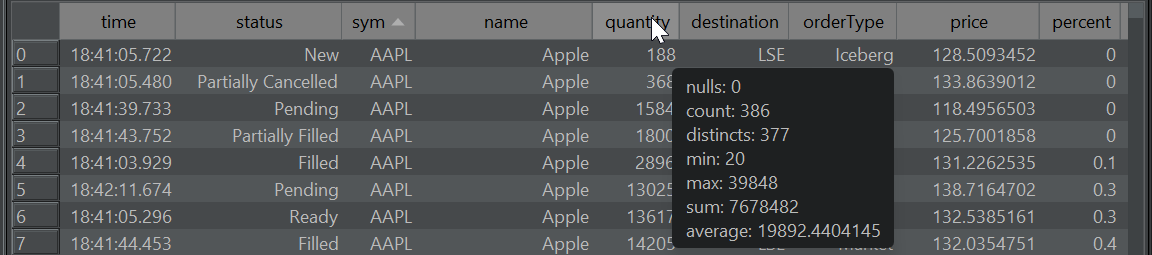
Column Stats
Allows getting a count of nulls, averages and how many distinct values a column contains by hovering the column header:
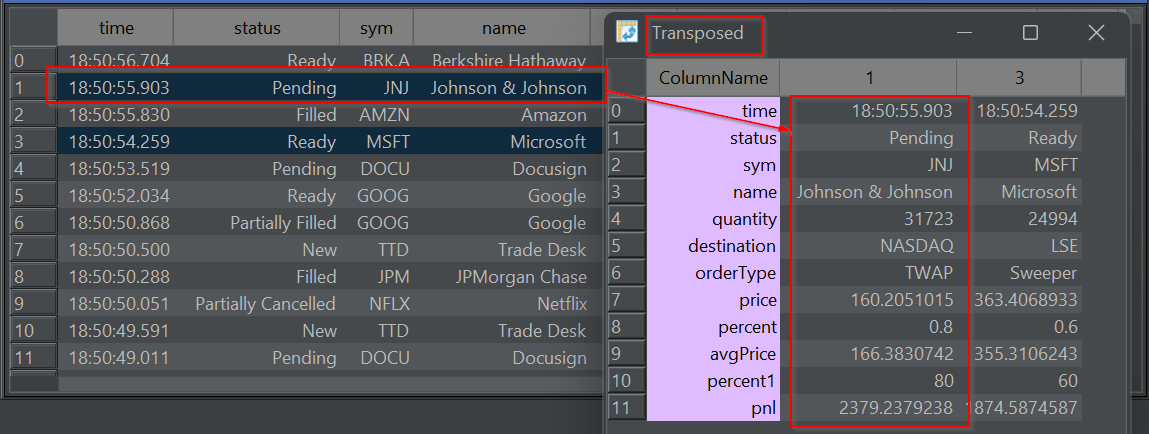
Transposed row(s)
Have a very wide table? Want to quickly see all the column?
Transpose from a row to column based layout for those rows. Allowing you to quickly see all values:
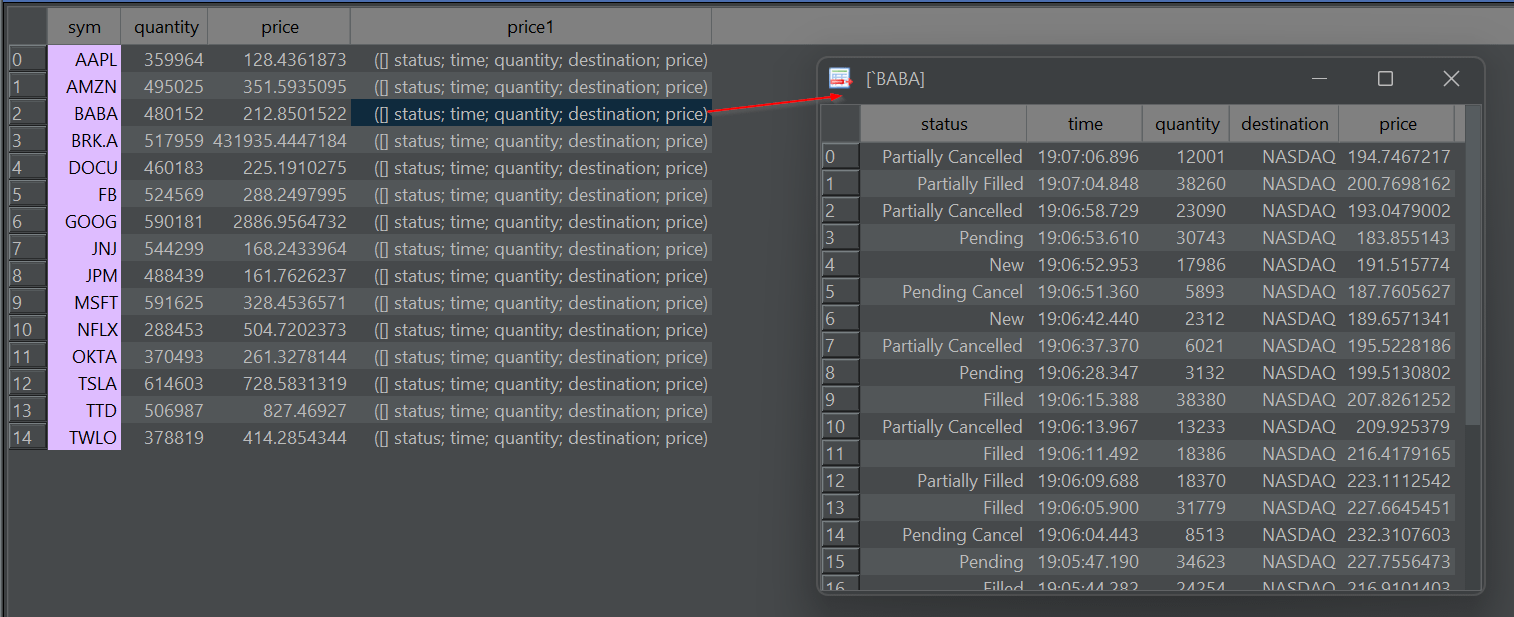
Dive-into Nested Results
Double-click on a nested array or kdb structure (table/dict) to pop-out a table showing only the nested item. You can repeat this to dig deeper and deeper into nested data. (Thanks to Oleg/QPad on pioneering this idea).
As well as these new features, a large number of bugs were fixed:
- 4K Monitor support was significantly improved. You have the option to scale the full UI in preferences.
- Apple Mac got a dedicated release and custom App download.
- We upgraded kdb+ c/jdbc.java to allow SSL TLS.
Full Release Info:
All past release changes can be found here.
2025-05-12 – 4.09 – Improve Autocomplete suggestions
– Add namespace listing panel.
– Improve QDoc to add file level details.
2025-04-22 – 4.08 – Bugfix: Candlestick charts were wrong as receiving wrong timezone from kdb driver. Timezone now set to UTC.
– Bugfix: “Save as” to .sql was shrinking text. Now fixed.
– Bugfix: Show red X close on every document tab.
2025-04-06 – 4.07 – Add UI Scaling and Font size as separate options to help with 4K monitors
– Bugfix: Kdb+ Queries with errors could cause 30 second freezes.
– Bugfix: Switch back to MonoSpaced font. Variable width fonts cause wrong caret position.
– Improved high resolution QStudio icon.
– Mac: Bugfix: Prefences dialog fixed and allows choosing font.
– Mac: Fixed Menu shoing about/preferences/exit.
– Mac: Allow Command+Option+E to run current query.
– 4K handling improved sizing of dialogs.
– Bugfix: Improved duckdb init when folder is empty.
2025-03-13 – 4.06 – Add ability to transpose rows.
– DuckDB 1.2.1. Improve display of DuckDB arrays.
– Add comma separator for thousands option.
2025-02-23 – 4.05 – Upgrade kdb+ c/jdbc.java to allow SSL TLS.
– Add preference to allow hiding all tooltips.
– Double-click on kdb+ table with dictionary/table/list nested in cell will pop it out.
2025-01-23 – 4.04 – Show column info (avg/min/max) when column header is hovered.
– Remove watched expressions entirely.
– Improved UI threading for tree/chart display.
May 9th, 2025 by admin
2025-05-08 – Private equity firm TA announced an “All-Cash Offer to Acquire FD Technologies, Owner of Global Real-Time Analytics Leader KX”.
Most people are probably wondering how this came about:
- 1996 – Brian established First Derivatives (FD) in 1996 from his mother’s spare bedroom (Newry, Northern Ireland) with a loan of £5,000 from the Credit Union.
- 1993 – Arthur Whitney and Janet Lustgarten jointly form the company KX
- 1998 – Kdb+ – In-memory column based database created by KX
- KX and FD work in partnership to grow the business.
- 2014-10 – First Derivatives acquires a controlling stake in Kx Systems.
- 2018 – FD agrees to buy out minority Kx Systems shareholders (Arthur and Janet)
- 2019 – First Derivatives completes acquisition of the minority shareholdings in Kx Systems, taking the company’s total stake in the business to 100 per cent for $53.8 million (€48m) in cash.
“The deal marks an important milestone for the company”, chief executive Brian Conlon said.
- 2019-07-28 – Brian Conlon, one of Northern Ireland’s most successful businessmen passes away. (link)
- 2020-01 – Seamus Keating appointed as CEO
- 2024-03 – FD Technologies broken into 3 separate firms:
- MRP – Marketing (spun off into a merger)
- First Derivative consulting arm.
- FD Technologies owning the KX software business
- 2024-12 – FD Technologies plc (LON:FDP) completes sale of First Derivative (consultancy) to EPAM Systems, Inc..
- 2025-05-08 – Private equity firm TA announced an “All-Cash Offer to Acquire FD Technologies, Owner of Global Real-Time Analytics Leader KX”.
March 2nd, 2025 by Ryan Hamilton
Releasing dashboards from file to allow git file based deploys:
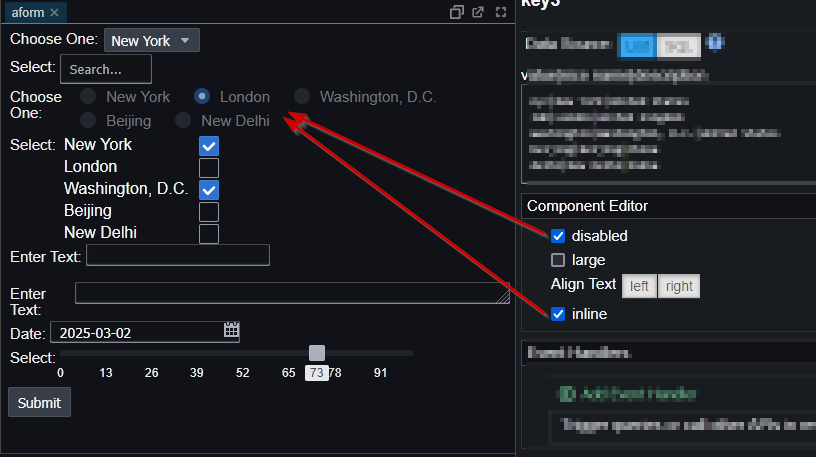
Improved Form Customization with radio/checkbox inline/disabled/large options. Allow specifying step size and labels for numeric slider.
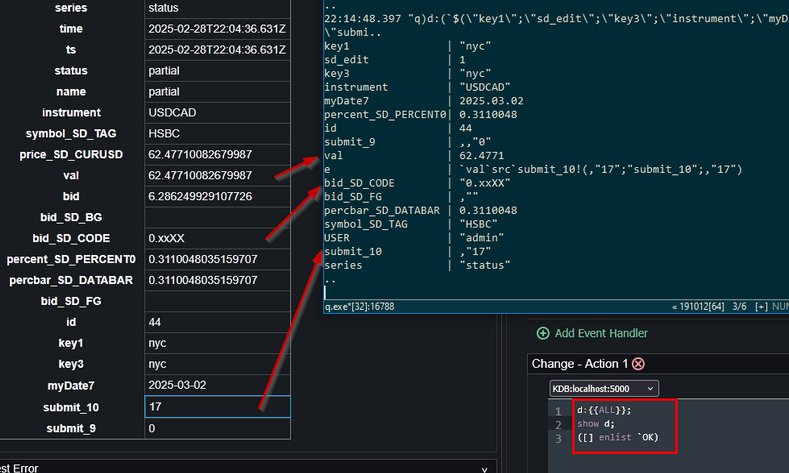
Send {{ALL}} variables to kdb+ as a nested dictionary:
December 6th, 2024 by Ryan Hamilton
QStudio is now 100% Free. No registration or license required.

Why? Are you shutting down?
Quite the opposite, we believe free and open source is the future and that is where we are going.
If anything we want customers to take this as a massive thanks.
Thank you for being part of driving QStudio forward and sponsoring development and cheering us along all these years.
Thanks in particular to
Thanks in particular to the large finance firms that took a chance on us. Big firms can be bureaucratic with onboarding, purchasing policies, vendor lists, 30 page contracts so I want to thanks all those individuals that jumped those hurdles to get us onboarded and those that put it on the corporate credit card. Below this post is an image containing what may or may not be some customers and other firms that have provided feedback, assistance and input over the years. Strictly speaking we are not allowed to confirm nor deny customers.
What I would say as an external party is that on average these places knew how to complete paperwork, get out of staffs way and enable them to get work done so they are probably better places to work on average.

Over the years, a few larger firms failed to onboard as those attempting it were ground down under the paperwork.
The good news for them is that QStudio is now free and the paperwork should be halved!
We look forward to improving QStudio together.
Being Free opens up more opportunities, please:
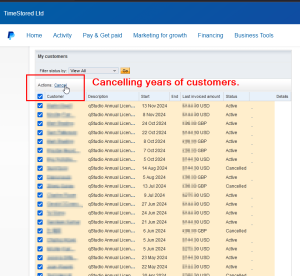
This is me cancelling all the individual users that paid annually for QStudio after 10+ years of building them up! Similarly all corporate contracts are also terminated.
Thanks
Note: For those who recently renewed we are offering a Free Pulse license for 10x the users you purchased for QStudio. Get in touch for a demo.