HTML Grid Live Update Performance
Pulse is specialized for real-time interactive data, as such it needs to be fast, very fast. When we first started building Pulse, we benchmarked all the grid components we could find and found that slick grid was just awesome, 60East did a fantastic writeup on how Slick grid compares to others. As we have added more features, e.g. column formatting, row formatting, sparklines…..it’s important to constantly monitor and test performance. We have:
- Automated tests that check the visual output is correct.
- Throughput tests to check we can process data fast enough
- Manual tests to ensure subtle human interactions work.
- Memory leak checks as our dashboards can be very long running.
Today I wanted to highlight how our throughput tests work by looking at our grid component.
HTML Table Throughput Testing
To test throughput we:
- Use scenarios as close to our customers typical use cases as possible.
- The most common query being a medium sized scrolling trade blotters with numerical/date formatting and row highlighting.
- 200 rows of data, scrolling 50 rows each update.
- We use a subscription connection to replay and render 1000s of data points as fast as possible.
Video Demonstrating 21,781 rows being replayed as 435 snapshots taking 16 seconds = 27 Updates per second. (European TV updates at 25 FPS).
Update: After this video we continued making improvements and with a few days more work got to 40 FPS.
Profiling Slick Grid Table
Breakdown
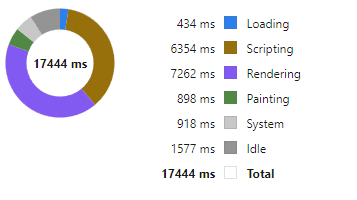
We then examine in detail where time is being spent. For example we:
- Turn on/off all formatting, all rendering options.
- Add/Remove columns
- Change screen sizes
- Change whether edit mode is on or table cells have been select (Off fact: selecting a cell makes the grid 30% slower to update)
Then we try to improve it!
Often this is looking at micro optimizations such as reducing the number of objects created. For example the analysis of how to format columns is only performed when columns change not when data is updated with the same schema. The really large wins tend to be optimizing for specific scenarios, e.g. a lot of our data is timestamped and received mostly in order. But those optimization are for a later post.